1.4 — Data Wrangling in the tidyverse
ECON 480 • Econometrics • Fall 2020
Ryan Safner
Assistant Professor of Economics
safner@hood.edu
ryansafner/metricsF20
metricsF20.classes.ryansafner.com
tibble: friendlier dataframes
magrittr: piping code
readr: importing data
dplyr: wrangling data
dplyr::filter(): select observations
dplyr::arrange(): reorder observations
dplyr::select(): select variables
dplyr::rename(): rename variables
dplyr::mutate(): create new variables
dplyr::summarize(): create statistics
tidyr: reshaping data
dplyr: combining datasets
Data Wrangling
- Most data analysis is taming chaos into order
- Data strewn from multiple sources 😨
- Missing data ("
NA") 😡 - Data not in a readable form 🤢

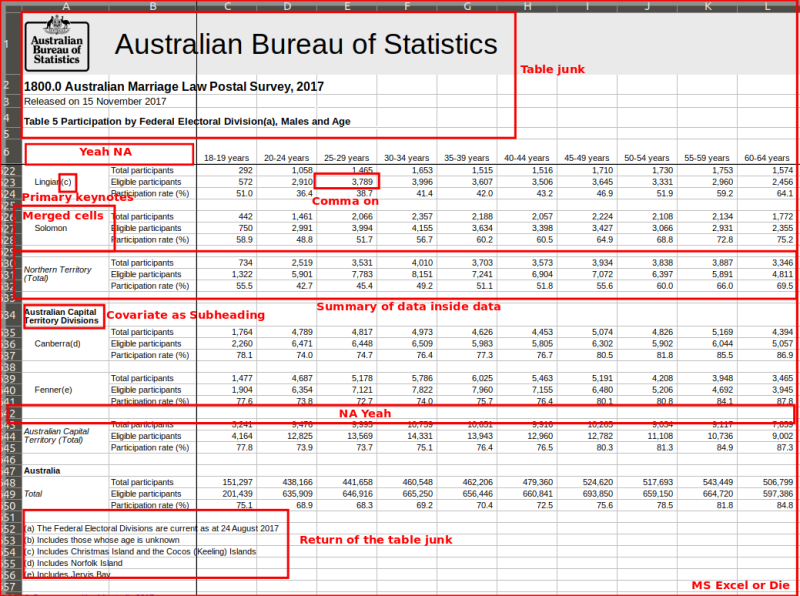
Workflow of a Data Scientist I
- Import raw data from out there in the world
- Tidy it into a form that you can use
- Explore the data (do these 3 repetitively!)
- Transform
- Visualize
- Model
- Communicate results to target audience
Ideally, you'd want to be able to do all of this in one program
Workflow of a Data Scientist II

"Yet far too much handcrafted work - what data scientists call "data wrangling," "data munging," and "data janitor work" - is still required. Data scientists, according to interviews and expert estimates, spend from 50 to 80 percent of their time mired in this more mundane labor of collecting and preparing unruly digital data, before it can be explored for useful nuggets."
The tidyverse I
"The tidyverse is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures.
- Allows you to do all of those things with one (set of) package(s)!
- Learn more at tidyverse.org
The tidyverse II
- Easiest to just load the core tidyverse all at once
- First install may take a few minutes - installs a lot of packages!
- Note loading the tidyverse is "noisy", it will spew a lot of messages
- Hide them with
suppressPackageStartupMessages()and insertlibrary()command inside
# install for first time# install.packages("tidyverse") # this takes a few minutes and may give several prompts# load tidyverse suppressPackageStartupMessages(library("tidyverse"))The tidyverse III
tidyversecontains a lot of packages, not all are loaded automatically
tidyverse_packages()## [1] "broom" "cli" "crayon" "dbplyr" "dplyr" ## [6] "forcats" "ggplot2" "haven" "hms" "httr" ## [11] "jsonlite" "lubridate" "magrittr" "modelr" "pillar" ## [16] "purrr" "readr" "readxl" "reprex" "rlang" ## [21] "rstudioapi" "rvest" "stringr" "tibble" "tidyr" ## [26] "xml2" "tidyverse"Your Workflow in the tidyverse:
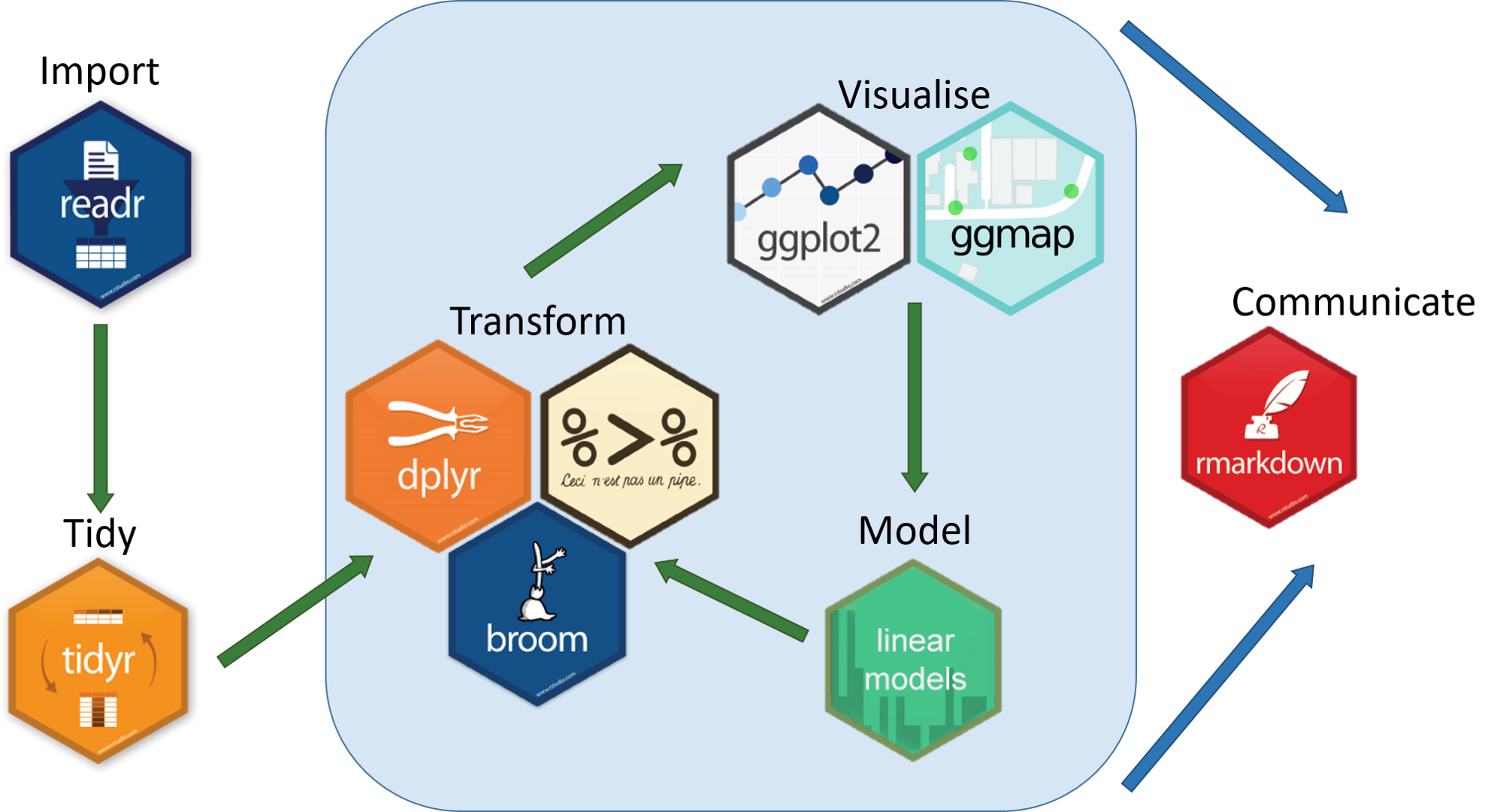
Tidyverse Packages
- We will make extensive use of (and talk today about):
tibblefor friendlier dataframesmagrittrfor "pipeable" codereadrfor importing datadplyrfor data wranglingtidyrfor tidying dataggplot2for plotting data (we've already covered)
- We will (or might) later look at:
broomfor tidy regression (not part of core tidyverse)forcatsfor working with factorsstringrfor working with stringslubridatefor working with dates and timespurrrfor iteration
tibble: friendlier dataframes
tibble I

tibbleconverts alldata.framesinto a friendlier version calledtibbles(ortbl_df)
tibble II
diamonds## # A tibble: 53,940 x 7## carat cut color clarity depth table price## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int>## 1 0.23 Ideal E SI2 61.5 55 326## 2 0.21 Premium E SI1 59.8 61 326## 3 0.23 Good E VS1 56.9 65 327## 4 0.290 Premium I VS2 62.4 58 334## 5 0.31 Good J SI2 63.3 58 335## 6 0.24 Very Good J VVS2 62.8 57 336## 7 0.24 Very Good I VVS1 62.3 57 336## 8 0.26 Very Good H SI1 61.9 55 337## 9 0.22 Fair E VS2 65.1 61 337## 10 0.23 Very Good H VS1 59.4 61 338## # … with 53,930 more rowsPrints much nicer output
Shows a bit of the
structure:nrow() x ncol()<dbl>is numeric ("double")<ord>is an ordered factor<int>is an integer
Fundamental grammar of tidyverse:
- start with a tibble
- run a function on it
- output a new tibble
tibble III
- Create a
tibblefrom adata.framewithas_tibble()
as_tibble(mpg) # take built-in dataframe mpg- Create a
tibblefrom scratch withtibble(), works likedata.frame()
example<-tibble(x = seq(2,6,2), # sequence from 2 to 6 by 2's y = rnorm(3,0,1), # 3 random draws with mean 0, sd 1 colors = c("orange", "green", "blue"))example## # A tibble: 3 x 3## x y colors## <dbl> <dbl> <chr> ## 1 2 1.40 orange## 2 4 -0.439 green ## 3 6 -0.896 bluetibble IV
- Create a
tibblerow-by-row withtribble()
example_2<-tribble( ~x, ~y, ~color, # each variable name starts with ~ 2, 1.5, "orange", 4, 0.2, "green", 6, 0.8, "blue") # last element has no commaexample_2## # A tibble: 3 x 3## x y color ## <dbl> <dbl> <chr> ## 1 2 1.5 orange## 2 4 0.2 green ## 3 6 0.8 bluemagrittr: piping code
magrittr I

The
magrittrpackage allows us to use the "pipe" operator (%>%)†%>%"pipes" the output of the left of the pipe into the (1st) argument of the rightRunning a function
fon objectxasf(x)becomesx %>% fin pipeable form- i.e. "take
xand then run functionfon it"
- i.e. "take
† Keyboard shortcuts in R Studio: CTRL+Shift+M (Windows) or Cmd+Shift+M (Mac)
magrittr II
With ordinary math functions, read from outside ← (inside): g(f(x))
- i.e. take
xand perform functionf()onxand then take that result and perform functiong()on it
- i.e. take
With pipes, read operations from left → right:
x %>% f %>% gtake x and then perform function f on it, then perform function g on that result
- Read
%>%mentally as "and then"
magrittr III
Example
ln(exp(x))
- First, exponentiate x, then take the natural log of that (resulting in just x)
- In pipes:
x %>% exp() %>% ln()magrittr IV
Example
- Sequence: find keys, unlock car, drive to school, park
- Using nested functions in pseudo-"code":
park(drive(start_car(find("keys")), to = "campus"))- Using pipes:
find("keys") %>% start_car() %>% drive(to = "campus") %>% park()magrittr: Simple Example
# look at top 6 rowshead(gapminder) # use pipe insteadgapminder %>% head()## # A tibble: 6 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 779.## 2 Afghanistan Asia 1957 30.3 9240934 821.## 3 Afghanistan Asia 1962 32.0 10267083 853.## 4 Afghanistan Asia 1967 34.0 11537966 836.## 5 Afghanistan Asia 1972 36.1 13079460 740.## 6 Afghanistan Asia 1977 38.4 14880372 786.magrittr: More Involved Example
- These two methods produce the same output (average hightway mpg of Audi cars)
magrittr: More Involved Example
These two methods produce the same output (average hightway mpg of Audi cars)
Without the pipe
summarise(group_by(filter(mpg, manufacturer=="audi"), model), hwy_mean = mean(hwy))magrittr: More Involved Example
These two methods produce the same output (average hightway mpg of Audi cars)
Without the pipe
summarise(group_by(filter(mpg, manufacturer=="audi"), model), hwy_mean = mean(hwy))- Using the pipe
mpg %>% filter(manufacturer=="audi") %>% group_by(model) %>% summarise(hwy_mean = mean(hwy))## # A tibble: 3 x 2## model hwy_mean## <chr> <dbl>## 1 a4 28.3## 2 a4 quattro 25.8## 3 a6 quattro 24readr: importing data
readr

readrhelps load common spreadsheet files (.csv,.tsv) with simple commands:read_*(path/to/my_data.*)- where
*can be.csvor.tsv
- where
Often this is enough, but many more customizations possible
You can also export your data from R into a common spreadsheet file with:
write_*(my_df, path = path/to/file_name.*)- where
my_dfis the name of yourtibble, andfile_nameis the name of the file you want to save as
- where
Read more on the tidyverse website and the Readr Cheatsheet
Readxl and Haven: When Readr isn't Enough


- For other data types from software programs like Excel, STATA, SAS, and SPSS:
readxlhas equivalent commands for Excel data types:read_*("path/to/my/data.*")write_*(my_dataframe, path=path/to/file_name.*)- where
*can be.xlsor.xlsx
havenhas equivalent commands for other data types:read_*("path/to/my_data.dta")for STATA.dtafileswrite_*(my_dataframe, path=path/to/file_name.*)- where
*can be.dta(STATA),.sav(SPSS),.sas7bdat(SAS)
Common Import Issues I
Most common: "where the hell is my data file"??
Recall
Rlooks for files toread_*()in the default working directory (check what it is withgetwd(), change it withsetwd())You can tell
Rwhere this data is by making thepatha part of the file's name when importing- Use
..to "move up one folder" - Use
/to "enter a folder"
- Use
Either use an absolute path on your computer:
# Exampledf <- read_csv("C:/Documents and Settings/Ryan Safner/Downloads/my_data.csv")Common Import Issues II
Most common: "where the hell is my data file"??
Recall
Rlooks for files toread_*()in the default working directory (check what it is withgetwd(), change it withsetwd())You can tell
Rwhere this data is by making thepatha part of the file's name when importing- Use
..to "move up one folder" - Use
/to "enter a folder"
- Use
- Or use a relative path from R's working directory
# Example# If working directory is Documents, but data is in Downloads, like so: # # Ryan Safner/# |# |- Documents/# |- Downloads/# |- Photos/# |- Videos/df <- read_csv("../Downloads/my_data.csv")Common Import Issues III
Suggestion to make your data import easier: Download and move files to R's working directory
Your computer and working directory are different from mine (and others)
This is not a reproducible workflow!
We'll finally fix this next class with
R Projects- The working directory is set to the Project Folder by default
- Same for everyone on any computer!
dplyr: wrangling data
dplyr I

dplyruses more efficient & intuitive commands to manipulate tibblesBase Rgrammar passively runs functions on nouns:function(object)dplyrgrammar actively uses verbs:verb(df, conditions)†Three great features:
- Allows use of
%>%pipe operator - Input and output is always a
tibble - Shows the output from a manipulation, but does not save/overwrite as an object unless explicitly assigned to an object
df %>% verb(conditions)dplyr II
- Common
dplyrverbs
| Verb | Does |
|---|---|
filter() |
Keep only selected observations |
select() |
Keep only selected variables |
arrange() |
Reorder rows (e.g. in numerical order) |
mutate() |
Create new variables |
summarize() |
Collapse data into summary statistics |
group_by() |
Perform any of the above functions by groups/categories |
dplyr::filter(): select observations
dplyr::filter()
filterkeeps only selected observations (rows)
dplyr::filter()
filterkeeps only selected observations (rows)
# look only at African observations# syntax without the pipefilter(gapminder, continent=="Africa")# using the pipegapminder %>% filter(continent == "Africa")dplyr::filter()
filterkeeps only selected observations (rows)
# look only at African observations# syntax without the pipefilter(gapminder, continent=="Africa")# using the pipegapminder %>% filter(continent == "Africa")## # A tibble: 624 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Algeria Africa 1952 43.1 9279525 2449.## 2 Algeria Africa 1957 45.7 10270856 3014.## 3 Algeria Africa 1962 48.3 11000948 2551.## 4 Algeria Africa 1967 51.4 12760499 3247.## 5 Algeria Africa 1972 54.5 14760787 4183.## 6 Algeria Africa 1977 58.0 17152804 4910.## 7 Algeria Africa 1982 61.4 20033753 5745.## 8 Algeria Africa 1987 65.8 23254956 5681.## 9 Algeria Africa 1992 67.7 26298373 5023.## 10 Algeria Africa 1997 69.2 29072015 4797.## # … with 614 more rowsdplyr: saving and storing outputs I
dplyrfunctions never modify their inputs (i.e. never overwrite the originaltibble)- If you want to save a result, use
<-to assign it to a newtibble - If assigned, you will not see the output until you call up the new
tibbleby name
dplyr: saving and storing outputs I
dplyrfunctions never modify their inputs (i.e. never overwrite the originaltibble)- If you want to save a result, use
<-to assign it to a newtibble - If assigned, you will not see the output until you call up the new
tibbleby name
# base syntaxafrica <- filter(gapminder, continent=="Africa")# using the pipeafrica <- gapminder %>% filter(continent == "Africa")# look at new tibbleafrica## # A tibble: 624 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Algeria Africa 1952 43.1 9279525 2449.## 2 Algeria Africa 1957 45.7 10270856 3014.## 3 Algeria Africa 1962 48.3 11000948 2551.## 4 Algeria Africa 1967 51.4 12760499 3247.## 5 Algeria Africa 1972 54.5 14760787 4183.## 6 Algeria Africa 1977 58.0 17152804 4910.## 7 Algeria Africa 1982 61.4 20033753 5745.## 8 Algeria Africa 1987 65.8 23254956 5681.## 9 Algeria Africa 1992 67.7 26298373 5023.## 10 Algeria Africa 1997 69.2 29072015 4797.## # … with 614 more rowsdplyr: saving and storing outputs II
- If you want to both store and view the output at the same time, wrap the command in parentheses!
(africa <- gapminder %>% filter(continent == "Africa"))## # A tibble: 624 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Algeria Africa 1952 43.1 9279525 2449.## 2 Algeria Africa 1957 45.7 10270856 3014.## 3 Algeria Africa 1962 48.3 11000948 2551.## 4 Algeria Africa 1967 51.4 12760499 3247.## 5 Algeria Africa 1972 54.5 14760787 4183.## 6 Algeria Africa 1977 58.0 17152804 4910.## 7 Algeria Africa 1982 61.4 20033753 5745.## 8 Algeria Africa 1987 65.8 23254956 5681.## 9 Algeria Africa 1992 67.7 26298373 5023.## 10 Algeria Africa 1997 69.2 29072015 4797.## # … with 614 more rowsdplyr: saving and storing outputs III
- If you were to assign the output to the original
tibble, it would overwrite the original!
# base syntaxgapminder <- filter(gapminder, continent=="Africa")# using the pipegapminder <- gapminder %>% filter(continent == "Africa")# this overwrites gapminder!dplyr Conditionals
- In many data wrangling contexts, you will want to select data conditionally
- To a computer: observations for which a set of logical conditions are
TRUE† >,<: greater than, less than>=,<=: greater than or equal to, less than or equal to==‡,!=: is equal to‡, is not equal to%in%: is a member of some defined set (∈)&: AND (commas also work instead)|: OR!: not
- To a computer: observations for which a set of logical conditions are
† See ?Comparison and ?Base::Logic.
‡ Recall one = assigns values to an object, two == tests an object for a condition!
dplyr::filter() with Conditionals
# look only at African observations# in 1997gapminder %>% filter(continent == "Africa", year == 1997)dplyr::filter() with Conditionals
# look only at African observations# in 1997gapminder %>% filter(continent == "Africa", year == 1997)## # A tibble: 52 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Algeria Africa 1997 69.2 29072015 4797.## 2 Angola Africa 1997 41.0 9875024 2277.## 3 Benin Africa 1997 54.8 6066080 1233.## 4 Botswana Africa 1997 52.6 1536536 8647.## 5 Burkina Faso Africa 1997 50.3 10352843 946.## 6 Burundi Africa 1997 45.3 6121610 463.## 7 Cameroon Africa 1997 52.2 14195809 1694.## 8 Central African Republic Africa 1997 46.1 3696513 741.## 9 Chad Africa 1997 51.6 7562011 1005.## 10 Comoros Africa 1997 60.7 527982 1174.## # … with 42 more rowsdplyr::filter() with Conditionals II
# look only at African observations # or observations in 1997gapminder %>% filter(continent == "Africa" | year == 1997)dplyr::filter() with Conditionals II
# look only at African observations # or observations in 1997gapminder %>% filter(continent == "Africa" | year == 1997)## # A tibble: 714 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Afghanistan Asia 1997 41.8 22227415 635.## 2 Albania Europe 1997 73.0 3428038 3193.## 3 Algeria Africa 1952 43.1 9279525 2449.## 4 Algeria Africa 1957 45.7 10270856 3014.## 5 Algeria Africa 1962 48.3 11000948 2551.## 6 Algeria Africa 1967 51.4 12760499 3247.## 7 Algeria Africa 1972 54.5 14760787 4183.## 8 Algeria Africa 1977 58.0 17152804 4910.## 9 Algeria Africa 1982 61.4 20033753 5745.## 10 Algeria Africa 1987 65.8 23254956 5681.## # … with 704 more rowsdplyr::filter() with Conditionals III
# look only at U.S. and U.K. # observations in 2002gapminder %>% filter(country %in% c("United States", "United Kingdom"), year == 2002)dplyr::filter() with Conditionals III
# look only at U.S. and U.K. # observations in 2002gapminder %>% filter(country %in% c("United States", "United Kingdom"), year == 2002)## # A tibble: 2 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 United Kingdom Europe 2002 78.5 59912431 29479.## 2 United States Americas 2002 77.3 287675526 39097.dplyr::arrange(): reorder observations
dplyr::arrange() I
arrangereorders observations (rows) in a logical order- e.g. alphabetical, numeric, small to large
dplyr::arrange() I
arrangereorders observations (rows) in a logical order- e.g. alphabetical, numeric, small to large
# order by smallest to largest pop# syntax without the pipearrange(gapminder, pop)# using the pipegapminder %>% arrange(pop)dplyr::arrange() I
arrangereorders observations (rows) in a logical order- e.g. alphabetical, numeric, small to large
# order by smallest to largest pop# syntax without the pipearrange(gapminder, pop)# using the pipegapminder %>% arrange(pop)## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Sao Tome and Principe Africa 1952 46.5 60011 880.## 2 Sao Tome and Principe Africa 1957 48.9 61325 861.## 3 Djibouti Africa 1952 34.8 63149 2670.## 4 Sao Tome and Principe Africa 1962 51.9 65345 1072.## 5 Sao Tome and Principe Africa 1967 54.4 70787 1385.## 6 Djibouti Africa 1957 37.3 71851 2865.## 7 Sao Tome and Principe Africa 1972 56.5 76595 1533.## 8 Sao Tome and Principe Africa 1977 58.6 86796 1738.## 9 Djibouti Africa 1962 39.7 89898 3021.## 10 Sao Tome and Principe Africa 1982 60.4 98593 1890.## # … with 1,694 more rowsdplyr::arrange() II
- Break ties in the value of one variable with the values of additional variables
dplyr::arrange() II
- Break ties in the value of one variable with the values of additional variables
# order by year, with the smallest # to largest pop in each year# syntax without the pipearrange(gapminder, year, pop)# using the pipegapminder %>% arrange(year, pop)dplyr::arrange() II
- Break ties in the value of one variable with the values of additional variables
# order by year, with the smallest # to largest pop in each year# syntax without the pipearrange(gapminder, year, pop)# using the pipegapminder %>% arrange(year, pop)## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Sao Tome and Principe Africa 1952 46.5 60011 880.## 2 Djibouti Africa 1952 34.8 63149 2670.## 3 Bahrain Asia 1952 50.9 120447 9867.## 4 Iceland Europe 1952 72.5 147962 7268.## 5 Comoros Africa 1952 40.7 153936 1103.## 6 Kuwait Asia 1952 55.6 160000 108382.## 7 Equatorial Guinea Africa 1952 34.5 216964 376.## 8 Reunion Africa 1952 52.7 257700 2719.## 9 Gambia Africa 1952 30 284320 485.## 10 Swaziland Africa 1952 41.4 290243 1148.## # … with 1,694 more rowsdplyr::arrange() III
- Use
desc()to re-order in the opposite direction
dplyr::arrange() III
- Use
desc()to re-order in the opposite direction
# order by largest to smallest pop# syntax without the pipearrange(gapminder, desc(pop))# using the pipegapminder %>% arrange(desc(pop))dplyr::arrange() III
- Use
desc()to re-order in the opposite direction
# order by largest to smallest pop# syntax without the pipearrange(gapminder, desc(pop))# using the pipegapminder %>% arrange(desc(pop))## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 China Asia 2007 73.0 1318683096 4959.## 2 China Asia 2002 72.0 1280400000 3119.## 3 China Asia 1997 70.4 1230075000 2289.## 4 China Asia 1992 68.7 1164970000 1656.## 5 India Asia 2007 64.7 1110396331 2452.## 6 China Asia 1987 67.3 1084035000 1379.## 7 India Asia 2002 62.9 1034172547 1747.## 8 China Asia 1982 65.5 1000281000 962.## 9 India Asia 1997 61.8 959000000 1459.## 10 China Asia 1977 64.0 943455000 741.## # … with 1,694 more rowsdplyr::select(): select variables
dplyr::select() I
selectkeeps only selected variables (columns)- Don't need quotes around column names
dplyr::select() I
selectkeeps only selected variables (columns)- Don't need quotes around column names
# keep only country, year, # and population variables# syntax without the pipeselect(gapminder, country, year, pop)# using the pipegapminder %>% select(country, year, pop)dplyr::select() I
selectkeeps only selected variables (columns)- Don't need quotes around column names
# keep only country, year, # and population variables# syntax without the pipeselect(gapminder, country, year, pop)# using the pipegapminder %>% select(country, year, pop)## # A tibble: 1,704 x 3## country year pop## <fct> <int> <int>## 1 Afghanistan 1952 8425333## 2 Afghanistan 1957 9240934## 3 Afghanistan 1962 10267083## 4 Afghanistan 1967 11537966## 5 Afghanistan 1972 13079460## 6 Afghanistan 1977 14880372## 7 Afghanistan 1982 12881816## 8 Afghanistan 1987 13867957## 9 Afghanistan 1992 16317921## 10 Afghanistan 1997 22227415## # … with 1,694 more rowsdplyr::select() II
select"all except" by negating a variable with-
dplyr::select() II
select"all except" by negating a variable with-
# keep all *except* gdpPercap# syntax without the pipeselect(gapminder, -gdpPercap)# using the pipegapminder %>% select(-gdpPercap)dplyr::select() II
select"all except" by negating a variable with-
# keep all *except* gdpPercap# syntax without the pipeselect(gapminder, -gdpPercap)# using the pipegapminder %>% select(-gdpPercap)## # A tibble: 1,704 x 5## country continent year lifeExp pop## <fct> <fct> <int> <dbl> <int>## 1 Afghanistan Asia 1952 28.8 8425333## 2 Afghanistan Asia 1957 30.3 9240934## 3 Afghanistan Asia 1962 32.0 10267083## 4 Afghanistan Asia 1967 34.0 11537966## 5 Afghanistan Asia 1972 36.1 13079460## 6 Afghanistan Asia 1977 38.4 14880372## 7 Afghanistan Asia 1982 39.9 12881816## 8 Afghanistan Asia 1987 40.8 13867957## 9 Afghanistan Asia 1992 41.7 16317921## 10 Afghanistan Asia 1997 41.8 22227415## # … with 1,694 more rowsdplyr::select() III
selectreorders the columns in the order you provide- sometimes useful to keep all variables, and drag one or a few to the front, add
everything()at the end
- sometimes useful to keep all variables, and drag one or a few to the front, add
dplyr::select() III
selectreorders the columns in the order you provide- sometimes useful to keep all variables, and drag one or a few to the front, add
everything()at the end
- sometimes useful to keep all variables, and drag one or a few to the front, add
# keep all and move pop first# syntax without the pipeselect(gapminder, pop, everything())# using the pipegapminder %>% select(pop, everything())dplyr::select() III
selectreorders the columns in the order you provide- sometimes useful to keep all variables, and drag one or a few to the front, add
everything()at the end
- sometimes useful to keep all variables, and drag one or a few to the front, add
# keep all and move pop first# syntax without the pipeselect(gapminder, pop, everything())# using the pipegapminder %>% select(pop, everything())## # A tibble: 1,704 x 6## pop country continent year lifeExp gdpPercap## <int> <fct> <fct> <int> <dbl> <dbl>## 1 8425333 Afghanistan Asia 1952 28.8 779.## 2 9240934 Afghanistan Asia 1957 30.3 821.## 3 10267083 Afghanistan Asia 1962 32.0 853.## 4 11537966 Afghanistan Asia 1967 34.0 836.## 5 13079460 Afghanistan Asia 1972 36.1 740.## 6 14880372 Afghanistan Asia 1977 38.4 786.## 7 12881816 Afghanistan Asia 1982 39.9 978.## 8 13867957 Afghanistan Asia 1987 40.8 852.## 9 16317921 Afghanistan Asia 1992 41.7 649.## 10 22227415 Afghanistan Asia 1997 41.8 635.## # … with 1,694 more rowsdplyr::select() IV
selecthas a lot of helper functions, useful for when you have hundreds of variables- see
?select()for a list
- see
dplyr::select() IV
selecthas a lot of helper functions, useful for when you have hundreds of variables- see
?select()for a list
- see
# keep all variables starting with "co"gapminder %>% select(starts_with("co"))## # A tibble: 1,704 x 2## country continent## <fct> <fct> ## 1 Afghanistan Asia ## 2 Afghanistan Asia ## 3 Afghanistan Asia ## 4 Afghanistan Asia ## 5 Afghanistan Asia ## 6 Afghanistan Asia ## 7 Afghanistan Asia ## 8 Afghanistan Asia ## 9 Afghanistan Asia ## 10 Afghanistan Asia ## # … with 1,694 more rowsdplyr::select() IV
selecthas a lot of helper functions, useful for when you have hundreds of variables- see
?select()for a list
- see
# keep all variables starting with "co"gapminder %>% select(starts_with("co"))## # A tibble: 1,704 x 2## country continent## <fct> <fct> ## 1 Afghanistan Asia ## 2 Afghanistan Asia ## 3 Afghanistan Asia ## 4 Afghanistan Asia ## 5 Afghanistan Asia ## 6 Afghanistan Asia ## 7 Afghanistan Asia ## 8 Afghanistan Asia ## 9 Afghanistan Asia ## 10 Afghanistan Asia ## # … with 1,694 more rows# keep country and all variables # containing "per"gapminder %>% select(country, contains("per"))## # A tibble: 1,704 x 2## country gdpPercap## <fct> <dbl>## 1 Afghanistan 779.## 2 Afghanistan 821.## 3 Afghanistan 853.## 4 Afghanistan 836.## 5 Afghanistan 740.## 6 Afghanistan 786.## 7 Afghanistan 978.## 8 Afghanistan 852.## 9 Afghanistan 649.## 10 Afghanistan 635.## # … with 1,694 more rowsdplyr::rename(): rename variables
dplyr::rename()
renamechanges the name of a variable (column)- Format:
new_name = old_name
- Format:
dplyr::rename()
renamechanges the name of a variable (column)- Format:
new_name = old_name
- Format:
# rename gdpPercap to GDP# syntax without the piperename(gapminder, GDP = gdpPercap)# using the pipegapminder %>% rename(GDP = gdpPercap)dplyr::rename()
renamechanges the name of a variable (column)- Format:
new_name = old_name
- Format:
# rename gdpPercap to GDP# syntax without the piperename(gapminder, GDP = gdpPercap)# using the pipegapminder %>% rename(GDP = gdpPercap)## # A tibble: 1,704 x 6## country continent year lifeExp pop GDP## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 779.## 2 Afghanistan Asia 1957 30.3 9240934 821.## 3 Afghanistan Asia 1962 32.0 10267083 853.## 4 Afghanistan Asia 1967 34.0 11537966 836.## 5 Afghanistan Asia 1972 36.1 13079460 740.## 6 Afghanistan Asia 1977 38.4 14880372 786.## 7 Afghanistan Asia 1982 39.9 12881816 978.## 8 Afghanistan Asia 1987 40.8 13867957 852.## 9 Afghanistan Asia 1992 41.7 16317921 649.## 10 Afghanistan Asia 1997 41.8 22227415 635.## # … with 1,694 more rowsdplyr::mutate(): create new variables

dplyr::mutate()
mutatecreates a new variable (column)- always adds a new column at the end
- general formula:
new_variable_name = operation
dplyr::mutate() II
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
dplyr::mutate() II
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
# create variable "europe" if country # is in Europe# syntax without the pipemutate(gapminder, europe = ifelse(continent == "Europe", yes = "In Europe", no = "Not in Europe"))# using the pipegapminder %>% mutate(europe = ifelse(continent == "Europe", yes = "In Europe", no = "Not in Europe"))dplyr::mutate() II
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
# create variable "europe" if country # is in Europe# syntax without the pipemutate(gapminder, europe = ifelse(continent == "Europe", yes = "In Europe", no = "Not in Europe"))# using the pipegapminder %>% mutate(europe = ifelse(continent == "Europe", yes = "In Europe", no = "Not in Europe"))## # A tibble: 1,704 x 4## country continent year europe ## <fct> <fct> <int> <chr> ## 1 Afghanistan Asia 1952 Not in Europe## 2 Afghanistan Asia 1957 Not in Europe## 3 Afghanistan Asia 1962 Not in Europe## 4 Afghanistan Asia 1967 Not in Europe## 5 Afghanistan Asia 1972 Not in Europe## 6 Afghanistan Asia 1977 Not in Europe## 7 Afghanistan Asia 1982 Not in Europe## 8 Afghanistan Asia 1987 Not in Europe## 9 Afghanistan Asia 1992 Not in Europe## 10 Afghanistan Asia 1997 Not in Europe## # … with 1,694 more rowsdplyr::mutate() III
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
dplyr::mutate() III
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
# create population in millions # syntax without the pipemutate(gapminder, pop_mil = pop / 1000000)# using the pipegapminder %>% rename(pop_mil = pop / 1000000)dplyr::mutate() III
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
# create population in millions # syntax without the pipemutate(gapminder, pop_mil = pop / 1000000)# using the pipegapminder %>% rename(pop_mil = pop / 1000000)## # A tibble: 1,704 x 6## country continent year lifeExp pop pop_mil## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 8.43## 2 Afghanistan Asia 1957 30.3 9240934 9.24## 3 Afghanistan Asia 1962 32.0 10267083 10.3 ## 4 Afghanistan Asia 1967 34.0 11537966 11.5 ## 5 Afghanistan Asia 1972 36.1 13079460 13.1 ## 6 Afghanistan Asia 1977 38.4 14880372 14.9 ## 7 Afghanistan Asia 1982 39.9 12881816 12.9 ## 8 Afghanistan Asia 1987 40.8 13867957 13.9 ## 9 Afghanistan Asia 1992 41.7 16317921 16.3 ## 10 Afghanistan Asia 1997 41.8 22227415 22.2 ## # … with 1,694 more rowsdplyr::mutate() IV
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
- Create a variable based on other variables
dplyr::mutate() IV
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
- Create a variable based on other variables
# create GDP variable from gdpPercap # and pop, in billions# syntax without the pipemutate(gapminder, GDP = ((gdpPercap * pop)/1000000000))# using the pipegapminder %>% mutate(GDP = ((gdpPercap * pop)/1000000000))dplyr::mutate() IV
- Three major types of mutates:
- Create a variable that is a specific value (often categorical)
- Change an existing variable (often rescaling)
- Create a variable based on other variables
# create GDP variable from gdpPercap # and pop, in billions# syntax without the pipemutate(gapminder, GDP = ((gdpPercap * pop)/1000000000))# using the pipegapminder %>% mutate(GDP = ((gdpPercap * pop)/1000000000))## # A tibble: 1,704 x 6## country continent year pop gdpPercap GDP## <fct> <fct> <int> <int> <dbl> <dbl>## 1 Afghanistan Asia 1952 8425333 779. 6.57## 2 Afghanistan Asia 1957 9240934 821. 7.59## 3 Afghanistan Asia 1962 10267083 853. 8.76## 4 Afghanistan Asia 1967 11537966 836. 9.65## 5 Afghanistan Asia 1972 13079460 740. 9.68## 6 Afghanistan Asia 1977 14880372 786. 11.7 ## 7 Afghanistan Asia 1982 12881816 978. 12.6 ## 8 Afghanistan Asia 1987 13867957 852. 11.8 ## 9 Afghanistan Asia 1992 16317921 649. 10.6 ## 10 Afghanistan Asia 1997 22227415 635. 14.1 ## # … with 1,694 more rowsdplyr::mutate() V
- Change
classof a variable insidemutate()withas.*()
gapminder %>% head(., 2)## # A tibble: 2 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 779.## 2 Afghanistan Asia 1957 30.3 9240934 821.# change year from an integer to a factorgapminder %>% mutate(year = as.factor(year))## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <fct> <dbl> <int> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 779.## 2 Afghanistan Asia 1957 30.3 9240934 821.## 3 Afghanistan Asia 1962 32.0 10267083 853.## 4 Afghanistan Asia 1967 34.0 11537966 836.## 5 Afghanistan Asia 1972 36.1 13079460 740.## 6 Afghanistan Asia 1977 38.4 14880372 786.## 7 Afghanistan Asia 1982 39.9 12881816 978.## 8 Afghanistan Asia 1987 40.8 13867957 852.## 9 Afghanistan Asia 1992 41.7 16317921 649.## 10 Afghanistan Asia 1997 41.8 22227415 635.## # … with 1,694 more rowsdplyr::mutate(): Multiple Variables
- Can create multiple new variables with commas:
dplyr::mutate(): Multiple Variables
- Can create multiple new variables with commas:
gapminder %>% mutate(GDP = gdpPercap * pop, pop_millions = pop / 1000000)## # A tibble: 1,704 x 8## country continent year lifeExp pop gdpPercap GDP pop_millions## <fct> <fct> <int> <dbl> <int> <dbl> <dbl> <dbl>## 1 Afghanist… Asia 1952 28.8 8425333 779. 6.57e 9 8.43## 2 Afghanist… Asia 1957 30.3 9240934 821. 7.59e 9 9.24## 3 Afghanist… Asia 1962 32.0 10267083 853. 8.76e 9 10.3 ## 4 Afghanist… Asia 1967 34.0 11537966 836. 9.65e 9 11.5 ## 5 Afghanist… Asia 1972 36.1 13079460 740. 9.68e 9 13.1 ## 6 Afghanist… Asia 1977 38.4 14880372 786. 1.17e10 14.9 ## 7 Afghanist… Asia 1982 39.9 12881816 978. 1.26e10 12.9 ## 8 Afghanist… Asia 1987 40.8 13867957 852. 1.18e10 13.9 ## 9 Afghanist… Asia 1992 41.7 16317921 649. 1.06e10 16.3 ## 10 Afghanist… Asia 1997 41.8 22227415 635. 1.41e10 22.2 ## # … with 1,694 more rowsdplyr::transmute()
transmutekeeps only newly created variables (selects only the newmutated variables)
gapminder %>% transmute(GDP = gdpPercap * pop, pop_millions = pop / 1000000)## # A tibble: 1,704 x 2## GDP pop_millions## <dbl> <dbl>## 1 6567086330. 8.43## 2 7585448670. 9.24## 3 8758855797. 10.3 ## 4 9648014150. 11.5 ## 5 9678553274. 13.1 ## 6 11697659231. 14.9 ## 7 12598563401. 12.9 ## 8 11820990309. 13.9 ## 9 10595901589. 16.3 ## 10 14121995875. 22.2 ## # … with 1,694 more rowsdplyr::mutate(): Conditionals
- Boolean, logical, and conditionals all work well in
mutate():
gapminder %>% select(country, year, lifeExp) %>% mutate(long_1 = lifeExp > 70, long_2 = ifelse(lifeExp > 70, "Long", "Short"))## # A tibble: 1,704 x 5## country year lifeExp long_1 long_2## <fct> <int> <dbl> <lgl> <chr> ## 1 Afghanistan 1952 28.8 FALSE Short ## 2 Afghanistan 1957 30.3 FALSE Short ## 3 Afghanistan 1962 32.0 FALSE Short ## 4 Afghanistan 1967 34.0 FALSE Short ## 5 Afghanistan 1972 36.1 FALSE Short ## 6 Afghanistan 1977 38.4 FALSE Short ## 7 Afghanistan 1982 39.9 FALSE Short ## 8 Afghanistan 1987 40.8 FALSE Short ## 9 Afghanistan 1992 41.7 FALSE Short ## 10 Afghanistan 1997 41.8 FALSE Short ## # … with 1,694 more rowsdplyr::mutate(): order Aware
mutate()is order-aware, so you can chain multiple mutates that depend on previous mutates
gapminder %>% select(country, year, lifeExp) %>% mutate(dog_years = lifeExp * 7, comment = paste("Life expectancy in", country, "is", dog_years, "in dog years.", sep = " "))## # A tibble: 1,704 x 5## country year lifeExp dog_years comment ## <fct> <int> <dbl> <dbl> <chr> ## 1 Afghanist… 1952 28.8 202. Life expectancy in Afghanistan is 201.607…## 2 Afghanist… 1957 30.3 212. Life expectancy in Afghanistan is 212.324…## 3 Afghanist… 1962 32.0 224. Life expectancy in Afghanistan is 223.979…## 4 Afghanist… 1967 34.0 238. Life expectancy in Afghanistan is 238.14 …## 5 Afghanist… 1972 36.1 253. Life expectancy in Afghanistan is 252.616…## 6 Afghanist… 1977 38.4 269. Life expectancy in Afghanistan is 269.066…## 7 Afghanist… 1982 39.9 279. Life expectancy in Afghanistan is 278.978…## 8 Afghanist… 1987 40.8 286. Life expectancy in Afghanistan is 285.754…## 9 Afghanist… 1992 41.7 292. Life expectancy in Afghanistan is 291.718…## 10 Afghanist… 1997 41.8 292. Life expectancy in Afghanistan is 292.341…## # … with 1,694 more rowsdplyr::mutate(): case_when()
case_whencreates a new variable with values that are conditional on values of other variables (e.g., "if/else")- Last argument:
TRUE: when
- Last argument:
gapminder %>% mutate(European = case_when( continent == "Europe" ~ "Aye", TRUE ~ "Nay" ))## # A tibble: 1,704 x 7## country continent year lifeExp pop gdpPercap European## <fct> <fct> <int> <dbl> <int> <dbl> <chr> ## 1 Afghanistan Asia 1952 28.8 8425333 779. Nay ## 2 Afghanistan Asia 1957 30.3 9240934 821. Nay ## 3 Afghanistan Asia 1962 32.0 10267083 853. Nay ## 4 Afghanistan Asia 1967 34.0 11537966 836. Nay ## 5 Afghanistan Asia 1972 36.1 13079460 740. Nay ## 6 Afghanistan Asia 1977 38.4 14880372 786. Nay ## 7 Afghanistan Asia 1982 39.9 12881816 978. Nay ## 8 Afghanistan Asia 1987 40.8 13867957 852. Nay ## 9 Afghanistan Asia 1992 41.7 16317921 649. Nay ## 10 Afghanistan Asia 1997 41.8 22227415 635. Nay ## # … with 1,694 more rowsdplyr::mutate(): scoped I
- "Scoped" variants of
mutatethat work on a subset of variables:mutate_all()affects every variablemutate_at()affects named or selected variablesmutate_if()affects variables that meet a criteria
# round all observations of numeric# variables to 2 digitsgapminder %>% mutate_if(is.numeric, round, digits = 2)## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <dbl> <dbl> <dbl> <dbl>## 1 Afghanistan Asia 1952 28.8 8425333 779.## 2 Afghanistan Asia 1957 30.3 9240934 821.## 3 Afghanistan Asia 1962 32 10267083 853.## 4 Afghanistan Asia 1967 34.0 11537966 836.## 5 Afghanistan Asia 1972 36.1 13079460 740.## 6 Afghanistan Asia 1977 38.4 14880372 786.## 7 Afghanistan Asia 1982 39.8 12881816 978.## 8 Afghanistan Asia 1987 40.8 13867957 852.## 9 Afghanistan Asia 1992 41.7 16317921 649.## 10 Afghanistan Asia 1997 41.8 22227415 635.## # … with 1,694 more rowsdplyr::mutate(): scoped II
- "Scoped" variants of
mutatethat work on a subset of variables:mutate_all()affects every variablemutate_at()affects named or selected variablesmutate_if()affects variables that meet a criteria
# make all factor variables uppercasegapminder %>% mutate_if(is.factor, toupper)## # A tibble: 1,704 x 6## country continent year lifeExp pop gdpPercap## <chr> <chr> <int> <dbl> <int> <dbl>## 1 AFGHANISTAN ASIA 1952 28.8 8425333 779.## 2 AFGHANISTAN ASIA 1957 30.3 9240934 821.## 3 AFGHANISTAN ASIA 1962 32.0 10267083 853.## 4 AFGHANISTAN ASIA 1967 34.0 11537966 836.## 5 AFGHANISTAN ASIA 1972 36.1 13079460 740.## 6 AFGHANISTAN ASIA 1977 38.4 14880372 786.## 7 AFGHANISTAN ASIA 1982 39.9 12881816 978.## 8 AFGHANISTAN ASIA 1987 40.8 13867957 852.## 9 AFGHANISTAN ASIA 1992 41.7 16317921 649.## 10 AFGHANISTAN ASIA 1997 41.8 22227415 635.## # … with 1,694 more rowsdplyr::mutate()
- Don't forget to assign the output to a new
tibble(or overwrite original) if you want to "save" the new variables!
dplyr::summarize(): create statistics
dplyr::summarize() I
summarize† outputs a tibble of desired summary statistics- can name the statistic variable as if you were
mutate-ing a new variable
- can name the statistic variable as if you were
dplyr::summarize() I
summarize† outputs a tibble of desired summary statistics- can name the statistic variable as if you were
mutate-ing a new variable
- can name the statistic variable as if you were
# get average life expectancy# call it avg_LEsummarize(gapminder, avg_LE = mean(lifeExp))# using the pipegapminder %>% summarize(avg_LE = mean(lifeExp))dplyr::summarize() I
summarize† outputs a tibble of desired summary statistics- can name the statistic variable as if you were
mutate-ing a new variable
- can name the statistic variable as if you were
# get average life expectancy# call it avg_LEsummarize(gapminder, avg_LE = mean(lifeExp))# using the pipegapminder %>% summarize(avg_LE = mean(lifeExp))## # A tibble: 1 x 1## avg_LE## <dbl>## 1 59.5† Also the more civilised non-U.S. English spelling summarise also works. dplyr was written by a Kiwi after all!
dplyr::summarize() II
- Useful
summarize()commands:
| Command | Does |
|---|---|
n()* |
Number of observations |
n_distinct()* |
Number of unique observations |
sum() |
Sum all observations of a variable |
mean() |
Average of all observations of a variable |
median() |
50th percentile of all observations of a variable |
sd() |
Standard deviation of all observations of a variable |
* Most commands require you to put a variable name inside the command's argument parentheses. These commands require nothing to be in parentheses!
dplyr::summarize() II
- Useful
summarize()commands (continued):
| Command | Does |
|---|---|
min() |
Minimum value of a variable |
max() |
Maximum value of a variable |
quantile(., 0.25)+ |
Specified percentile (example 25th percentile) of a variable |
first() |
First value of a variable |
last() |
Last value of a variable |
nth(., 2)+ |
Specified position of a variable (example 2nd) |
+ The . is where you would put your variable name.
dplyr::summarize() counts
- Counts of a categorical variable are useful, and can be done a few different ways:
dplyr::summarize() counts
- Counts of a categorical variable are useful, and can be done a few different ways:
# summarize with n() gives size of current group, has no argumentsgapminder %>% summarize(amount = n()) # I've called it "amount"## # A tibble: 1 x 1## amount## <int>## 1 1704dplyr::summarize() counts
- Counts of a categorical variable are useful, and can be done a few different ways:
# summarize with n() gives size of current group, has no argumentsgapminder %>% summarize(amount = n()) # I've called it "amount"## # A tibble: 1 x 1## amount## <int>## 1 1704# count() is a dedicated command, counts observations by specified variablegapminder %>% count(year) # counts how many observations per year## # A tibble: 12 x 2## year n## <int> <int>## 1 1952 142## 2 1957 142## 3 1962 142## 4 1967 142## 5 1972 142## 6 1977 142## 7 1982 142## 8 1987 142## 9 1992 142## 10 1997 142## 11 2002 142## 12 2007 142dplyr::summarize() Conditionally
- Can do counts and proportions by conditions
- How many observations fit specified conditions (e.g.
TRUE) - Numeric objects:
TRUE=1andFALSE=0sum(x)becomes the number ofTRUEs inxmean(x)becomes the proportion
- How many observations fit specified conditions (e.g.
dplyr::summarize() Conditionally
- Can do counts and proportions by conditions
- How many observations fit specified conditions (e.g.
TRUE) - Numeric objects:
TRUE=1andFALSE=0sum(x)becomes the number ofTRUEs inxmean(x)becomes the proportion
- How many observations fit specified conditions (e.g.
# How many countries have life expectancy# over 70 in 2007?gapminder %>% filter(year=="2007") %>% summarize(Over_70 = sum(lifeExp>70))## # A tibble: 1 x 1## Over_70## <int>## 1 83dplyr::summarize() Conditionally
- Can do counts and proportions by conditions
- How many observations fit specified conditions (e.g.
TRUE) - Numeric objects:
TRUE=1andFALSE=0sum(x)becomes the number ofTRUEs inxmean(x)becomes the proportion
- How many observations fit specified conditions (e.g.
# How many countries have life expectancy# over 70 in 2007?gapminder %>% filter(year=="2007") %>% summarize(Over_70 = sum(lifeExp>70))## # A tibble: 1 x 1## Over_70## <int>## 1 83# What *proportion* of countries have life# expectancy over 70 in 2007?gapminder %>% filter(year=="2007") %>% summarize(Over_70 = mean(lifeExp>70))## # A tibble: 1 x 1## Over_70## <dbl>## 1 0.585dplyr::summarize() Multiple Variables
- Can
summarize()multiple variables at once, separate by commas
# get average life expectancy and GDP # call each avg_LE, avg_GDPsummarize(gapminder, avg_LE = mean(lifeExp), avg_GDP = mean(gdpPercap))# using the pipegapminder %>% summarize(avg_LE = mean(lifeExp), avg_GDP = mean(gdpPercap))dplyr::summarize() Multiple Variables
- Can
summarize()multiple variables at once, separate by commas
# get average life expectancy and GDP # call each avg_LE, avg_GDPsummarize(gapminder, avg_LE = mean(lifeExp), avg_GDP = mean(gdpPercap))# using the pipegapminder %>% summarize(avg_LE = mean(lifeExp), avg_GDP = mean(gdpPercap))## # A tibble: 1 x 2## avg_LE avg_GDP## <dbl> <dbl>## 1 59.5 7215.dplyr::summarize() Multiple Statistics
- Can
summarize()multiple statistics of a variable at once, separate by commas
# get count, mean, sd, min, max# of life Expectancy summarize(gapminder, obs = n(), avg_LE = mean(lifeExp), sd_LE = sd(lifeExp), min_LE = min(lifeExp), max_LE = max(lifeExp))# using the pipegapminder %>% summarize(obs = n(), avg_LE = mean(lifeExp), sd_LE = sd(lifeExp), min_LE = min(lifeExp), max_LE = max(lifeExp))dplyr::summarize() Multiple Statistics
- Can
summarize()multiple statistics of a variable at once, separate by commas
# get count, mean, sd, min, max# of life Expectancy summarize(gapminder, obs = n(), avg_LE = mean(lifeExp), sd_LE = sd(lifeExp), min_LE = min(lifeExp), max_LE = max(lifeExp))# using the pipegapminder %>% summarize(obs = n(), avg_LE = mean(lifeExp), sd_LE = sd(lifeExp), min_LE = min(lifeExp), max_LE = max(lifeExp))## # A tibble: 1 x 5## obs avg_LE sd_LE min_LE max_LE## <int> <dbl> <dbl> <dbl> <dbl>## 1 1704 59.5 12.9 23.6 82.6dplyr::summarize() Multiple Statistics
- "Scoped" versions of
summarize()that work on a subset of variablessummarize_all(): affects every variablesummarize_at(): affects named or selected variablessummarize_if(): affects variables that meet a criteria
dplyr::summarize() Multiple Statistics
- "Scoped" versions of
summarize()that work on a subset of variablessummarize_all(): affects every variablesummarize_at(): affects named or selected variablessummarize_if(): affects variables that meet a criteria
# get the average of all# numeric variables gapminder %>% summarize_if(is.numeric, funs(avg = mean))## # A tibble: 1 x 4## year_avg lifeExp_avg pop_avg gdpPercap_avg## <dbl> <dbl> <dbl> <dbl>## 1 1980. 59.5 29601212. 7215.dplyr::summarize() Multiple Statistics
- "Scoped" versions of
summarize()that work on a subset of variablessummarize_all(): affects every variablesummarize_at(): affects named or selected variablessummarize_if(): affects variables that meet a criteria
# get the average of all# numeric variables gapminder %>% summarize_if(is.numeric, funs(avg = mean))## # A tibble: 1 x 4## year_avg lifeExp_avg pop_avg gdpPercap_avg## <dbl> <dbl> <dbl> <dbl>## 1 1980. 59.5 29601212. 7215.# get mean and sd for# pop and lifeExpgapminder %>% summarize_at(vars(pop, lifeExp), funs("avg" = mean, "std dev" = sd))## # A tibble: 1 x 4## pop_avg lifeExp_avg `pop_std dev` `lifeExp_std dev`## <dbl> <dbl> <dbl> <dbl>## 1 29601212. 59.5 106157897. 12.9dplyr::summarize() with group_by() I
If we have
factorvariables grouping a variable into categories, we can rundplyrverbs by group- Particularly useful for
summarize()
- Particularly useful for
First define the group with
group_by()
dplyr::summarize() with group_by() I
If we have
factorvariables grouping a variable into categories, we can rundplyrverbs by group- Particularly useful for
summarize()
- Particularly useful for
First define the group with
group_by()
# get average life expectancy and gdp by continent gapminder %>% group_by(continent) %>% summarize(mean_life = mean(lifeExp), mean_GDP = mean(gdpPercap))## # A tibble: 5 x 3## continent mean_life mean_GDP## <fct> <dbl> <dbl>## 1 Africa 48.9 2194.## 2 Americas 64.7 7136.## 3 Asia 60.1 7902.## 4 Europe 71.9 14469.## 5 Oceania 74.3 18622.dplyr::summarize() with group_by() II
# track changes in average life expectancy and gdp over time gapminder %>% group_by(year) %>% summarize(mean_life = mean(lifeExp), mean_GDP = mean(gdpPercap))## # A tibble: 12 x 3## year mean_life mean_GDP## <int> <dbl> <dbl>## 1 1952 49.1 3725.## 2 1957 51.5 4299.## 3 1962 53.6 4726.## 4 1967 55.7 5484.## 5 1972 57.6 6770.## 6 1977 59.6 7313.## 7 1982 61.5 7519.## 8 1987 63.2 7901.## 9 1992 64.2 8159.## 10 1997 65.0 9090.## 11 2002 65.7 9918.## 12 2007 67.0 11680.dplyr::summarize() with group_by() III
- Can group observations by multiple variables (in proper order)
# track changes in average life expectancy and gdp by continent over time gapminder %>% group_by(continent, year) %>% summarize(mean_life = mean(lifeExp), mean_GDP = mean(gdpPercap))## # A tibble: 60 x 4## # Groups: continent [5]## continent year mean_life mean_GDP## <fct> <int> <dbl> <dbl>## 1 Africa 1952 39.1 1253.## 2 Africa 1957 41.3 1385.## 3 Africa 1962 43.3 1598.## 4 Africa 1967 45.3 2050.## 5 Africa 1972 47.5 2340.## 6 Africa 1977 49.6 2586.## 7 Africa 1982 51.6 2482.## 8 Africa 1987 53.3 2283.## 9 Africa 1992 53.6 2282.## 10 Africa 1997 53.6 2379.## # … with 50 more rowsExample: Piping Across Packages
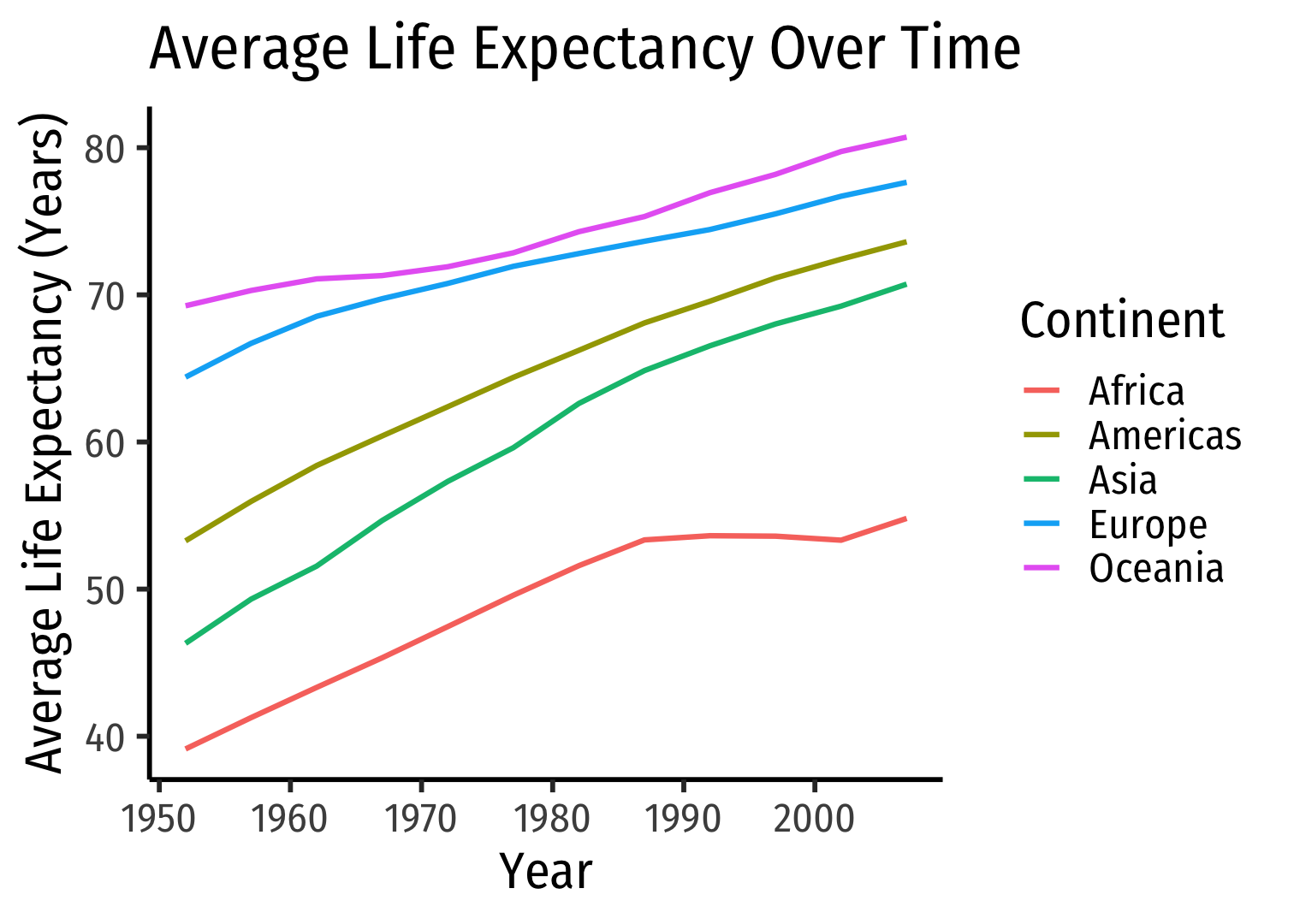
tidyverseuses same grammar and design philosophy- Example: graphing change in average life expectancy by continent over time
Example: Piping Across Packages
tidyverseuses same grammar and design philosophy- Example: graphing change in average life expectancy by continent over timegapminder %>%group_by(continent, year) %>%summarize(mean_life = mean(lifeExp),mean_GDP = mean(gdpPercap)) %>%# now pipe this tibble in as data for ggplot!ggplot(data = ., # . stands in for stuff ^!aes(x = year,y = mean_life,color = continent))+geom_path(size=1)+labs(x = "Year",y = "Average Life Expectancy (Years)",color = "Continent",title = "Average Life Expectancy Over Time")+theme_classic(base_family = "Fira Sans Condensed", base_size=20)
Example: Piping Across Packages
tidyverseuses same grammar and design philosophy- Example: graphing change in average life expectancy by continent over timegapminder %>%group_by(continent, year) %>%summarize(mean_life = mean(lifeExp),mean_GDP = mean(gdpPercap)) %>%# now pipe this tibble in as data for ggplot!ggplot(data = ., # . stands in for stuff ^!aes(x = year,y = mean_life,color = continent))+geom_path(size=1)+labs(x = "Year",y = "Average Life Expectancy (Years)",color = "Continent",title = "Average Life Expectancy Over Time")+theme_classic(base_family = "Fira Sans Condensed", base_size=20)
dplyr: Other Useful Commands I
tallyprovides counts, best used withgroup_byforfactors
dplyr: Other Useful Commands I
tallyprovides counts, best used withgroup_byforfactors
gapminder %>% tally## # A tibble: 1 x 1## n## <int>## 1 1704dplyr: Other Useful Commands I
tallyprovides counts, best used withgroup_byforfactors
gapminder %>% tally## # A tibble: 1 x 1## n## <int>## 1 1704gapminder %>% group_by(continent) %>% tally## # A tibble: 5 x 2## continent n## <fct> <int>## 1 Africa 624## 2 Americas 300## 3 Asia 396## 4 Europe 360## 5 Oceania 24dplyr: Other Useful Commands II
slice()subsets rows by position instead offiltering by values
dplyr: Other Useful Commands II
slice()subsets rows by position instead offiltering by values
gapminder %>% slice(15:17) # see 15th through 17th observations## # A tibble: 3 x 6## country continent year lifeExp pop gdpPercap## <fct> <fct> <int> <dbl> <int> <dbl>## 1 Albania Europe 1962 64.8 1728137 2313.## 2 Albania Europe 1967 66.2 1984060 2760.## 3 Albania Europe 1972 67.7 2263554 3313.dplyr: Other Useful Commands III
pull()extracts a column from atibble(just like$)
dplyr: Other Useful Commands III
pull()extracts a column from atibble(just like$)
# Get all U.S. life expectancy observationsgapminder %>% filter(country == "United States") %>% pull(lifeExp)## [1] 68.440 69.490 70.210 70.760 71.340 73.380 74.650 75.020 76.090 76.810## [11] 77.310 78.242dplyr: Other Useful Commands III
pull()extracts a column from atibble(just like$)
# Get all U.S. life expectancy observationsgapminder %>% filter(country == "United States") %>% pull(lifeExp)## [1] 68.440 69.490 70.210 70.760 71.340 73.380 74.650 75.020 76.090 76.810## [11] 77.310 78.242# Get U.S. life expectancy in 2007gapminder %>% filter(country == "United States" & year == 2007) %>% pull(lifeExp)## [1] 78.242dplyr: Other Useful Commands IV
distinct()shows the distinct values of a specified variable (recalln_distinct()insidesummarize()just gives you the number of values)
gapminder %>% distinct(country)## # A tibble: 142 x 1## country ## <fct> ## 1 Afghanistan## 2 Albania ## 3 Algeria ## 4 Angola ## 5 Argentina ## 6 Australia ## 7 Austria ## 8 Bahrain ## 9 Bangladesh ## 10 Belgium ## # … with 132 more rowstidyr: reshaping data

tidyr: reshaping and tidying data
tidyrhelps reshape data into more usable format- "tidy" data† are (an opinionated view of) data where
- Each variable is in a column
- Each observation is a row
- Each observational unit forms a table‡
- Spend less time fighting your tools and more time on analysis!
† This is the namesake of the tidyverse: all associated packages and functions use or require this data format!
‡ Alternatively, sometimes rule 3 is "every value is its own cell."
tidyr: Tidy Data
- "tidy" data ≠ clean, perfect data
"Happy families are all alike; every unhappy family is unhappy in its own way." - Leo Tolstoy
"Tidy datasets are all alike, but every messy dataset is messy in its own way." - Hadley Wickham

tidyr::gather() wide to long I
# make example untidy data ex_wide<-tribble( ~"Country", ~"2000", ~"2010", "United States", 140, 180, "Canada", 102, 98, "China", 111, 123)ex_wide## # A tibble: 3 x 3## Country `2000` `2010`## <chr> <dbl> <dbl>## 1 United States 140 180## 2 Canada 102 98## 3 China 111 123- Common source of "un-tidy" data: Column headers are values, not variable names! 😨
- Column names are values of a
yearvariable! - Each row represents two observations (one in 2000 and one in 2010)!
- Column names are values of a
tidyr::gather() wide to long II
# make example untidy data ex_wide<-tribble( ~"Country", ~"2000", ~"2010", "United States", 140, 180, "Canada", 102, 98, "China", 111, 123)ex_wide## # A tibble: 3 x 3## Country `2000` `2010`## <chr> <dbl> <dbl>## 1 United States 140 180## 2 Canada 102 98## 3 China 111 123- We need to
gather()these columns into a new pair of variables- set of columns that represent values, not variables (
2000and2010) key: name of variable whose values form the column names (we'll call it theyear)value: name of the variable whose values are spread over the cells (we'll call it number ofcases)
- set of columns that represent values, not variables (
tidyr::gather() wide to long III
gather()a wide data frame into a long data frame
ex_wide## # A tibble: 3 x 3## Country `2000` `2010`## <chr> <dbl> <dbl>## 1 United States 140 180## 2 Canada 102 98## 3 China 111 123ex_wide %>% gather("2000","2010", key = "year", value = "cases")## # A tibble: 6 x 3## Country year cases## <chr> <chr> <dbl>## 1 United States 2000 140## 2 Canada 2000 102## 3 China 2000 111## 4 United States 2010 180## 5 Canada 2010 98## 6 China 2010 123tidyr::spread() long to wide I
ex_long # example I made (code hidden)## # A tibble: 12 x 4## Country Year Type Count## <chr> <dbl> <chr> <dbl>## 1 United States 2000 Cases 140## 2 United States 2000 Population 300## 3 United States 2010 Cases 180## 4 United States 2010 Population 310## 5 Canada 2000 Cases 102## 6 Canada 2000 Population 110## 7 Canada 2010 Cases 98## 8 Canada 2010 Population 121## 9 China 2000 Cases 111## 10 China 2000 Population 1201## 11 China 2010 Cases 123## 12 China 2010 Population 1241- Another common source of "un-tidy" data: observations are scattered across multiple rows 😨
- Each country has two rows per observation, one for
Casesand one forPopulation(categorized bytypeof variable)
- Each country has two rows per observation, one for
tidyr::spread() long to wide II
ex_long # example I made (code hidden)## # A tibble: 12 x 4## Country Year Type Count## <chr> <dbl> <chr> <dbl>## 1 United States 2000 Cases 140## 2 United States 2000 Population 300## 3 United States 2010 Cases 180## 4 United States 2010 Population 310## 5 Canada 2000 Cases 102## 6 Canada 2000 Population 110## 7 Canada 2010 Cases 98## 8 Canada 2010 Population 121## 9 China 2000 Cases 111## 10 China 2000 Population 1201## 11 China 2010 Cases 123## 12 China 2010 Population 1241- We need to
spread()these columns into a new pair of variableskey: column that contains variable names (here, thetype)value: column that contains values from multiple variables (here, thecount)
tidyr::spread() long to wide III
spread()a long data frame into a wide data frame
ex_long## # A tibble: 12 x 4## Country Year Type Count## <chr> <dbl> <chr> <dbl>## 1 United States 2000 Cases 140## 2 United States 2000 Population 300## 3 United States 2010 Cases 180## 4 United States 2010 Population 310## 5 Canada 2000 Cases 102## 6 Canada 2000 Population 110## 7 Canada 2010 Cases 98## 8 Canada 2010 Population 121## 9 China 2000 Cases 111## 10 China 2000 Population 1201## 11 China 2010 Cases 123## 12 China 2010 Population 1241ex_long %>% spread(key = "Type", value = "Count")## # A tibble: 6 x 4## Country Year Cases Population## <chr> <dbl> <dbl> <dbl>## 1 Canada 2000 102 110## 2 Canada 2010 98 121## 3 China 2000 111 1201## 4 China 2010 123 1241## 5 United States 2000 140 300## 6 United States 2010 180 310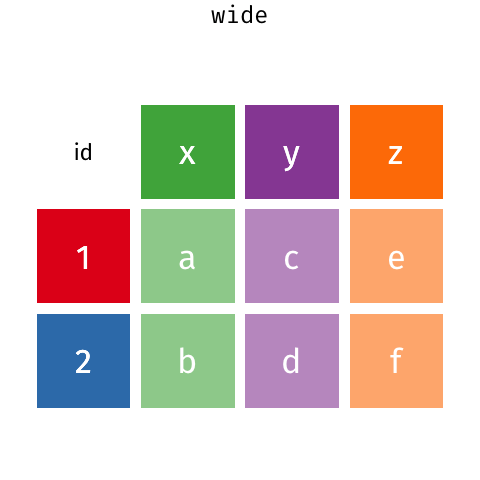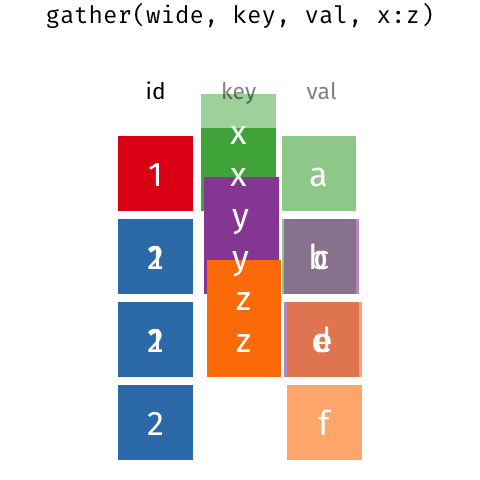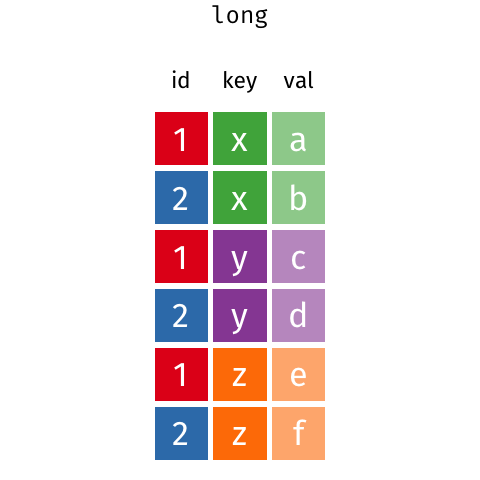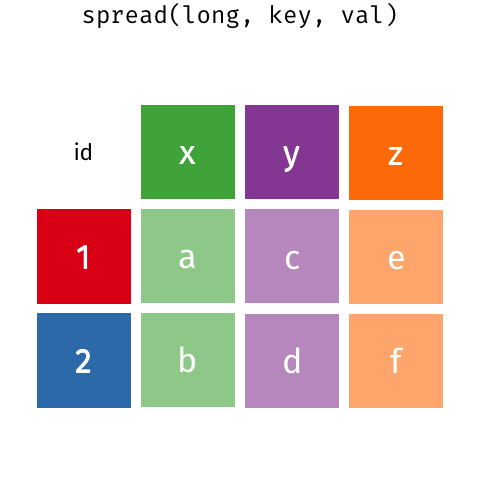
Combining Datasets

Combining Datasets
Often, data doesn't come from just one source, but several sources
We can combine datasets into a single dataframe (tibble) using
dplyrcommands in several ways:binddataframes together by row or by columnbind_rows()adds observations (rows) to existing dataset1bind_cols()adds variables (columns) to existing dataset2
jointwo dataframes by designating variable(s) askeyto match rows by identical values of thatkey
† Note the columns must be identical between the original dataset and the new observations
‡ Note the rows must be identical between original dataset and new variable
Two Similar Datasets I
Sometimes you want to add rows (observations) or columns (variables) that happen to match up perfectly
- New observations contain all the same variables as existing data
- OR
- New variables contain all the same observations as existing data
In this case, simply using
bind_*(old_df, new_df)will workbind_columns(old_df, new_df)adds columns fromnew_dftoold_dfbind_rows(old_df, new_df)adds rows fromnew_dftoold_df
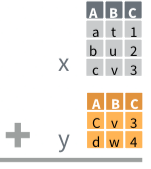
Two Similar Datasets II
bind_columns() (Variables)
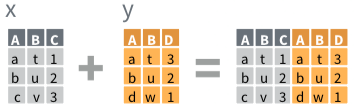
bind_rows() (Observations)
Two Different Datasets
- For the following examples, consider the following two dataframes,
xandy*- each has one unique variable,
x$xandy$y - both have values for observations
1and2 xhas observation3whichydoes not haveyhas observation4whichxdoes not have
- each has one unique variable,
- We next consider the ways we can merge dataframes
xandyinto a single dataframe
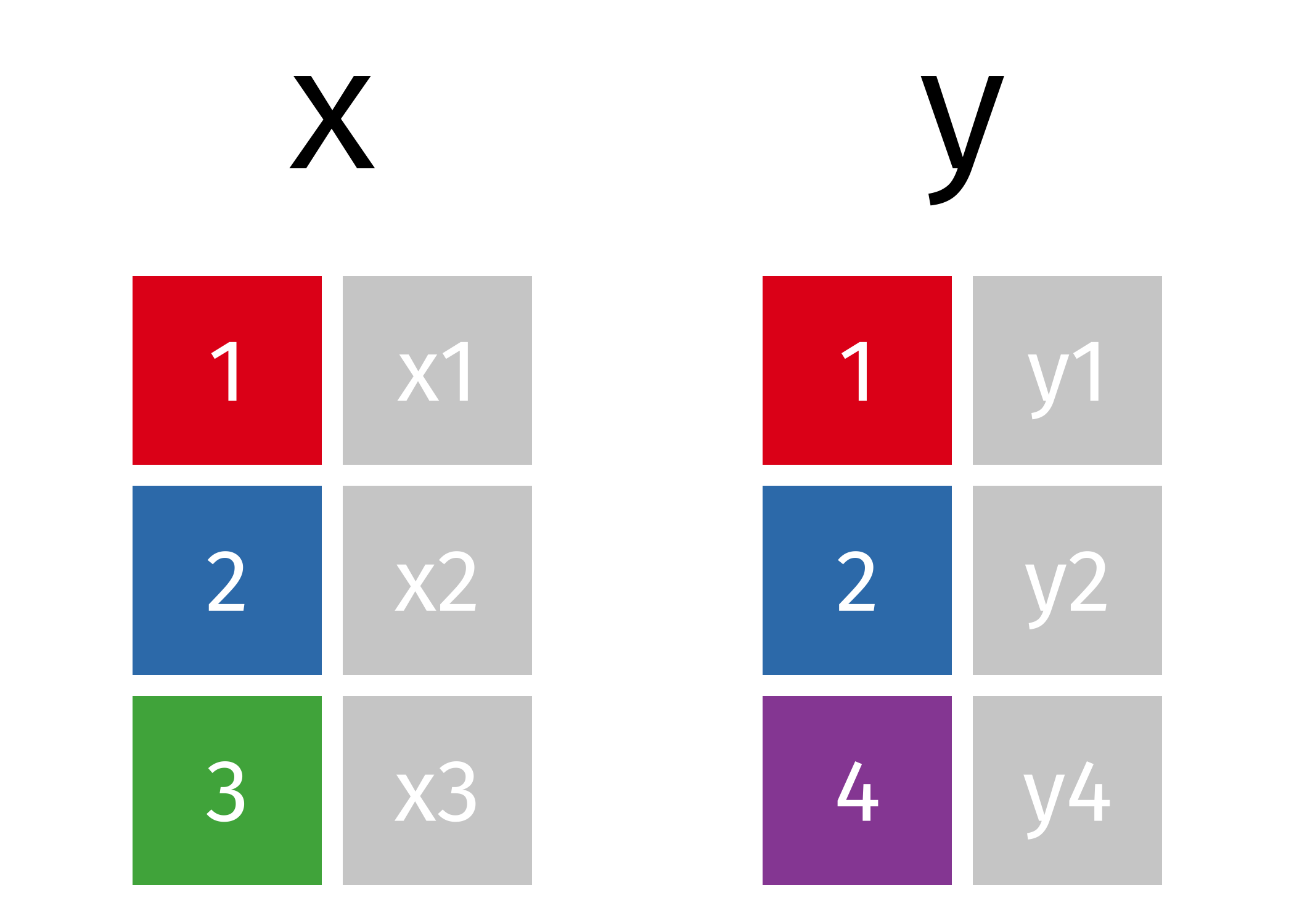
* Images on all following slides come from Garrick Aden-Buie's excellent tidyexplain
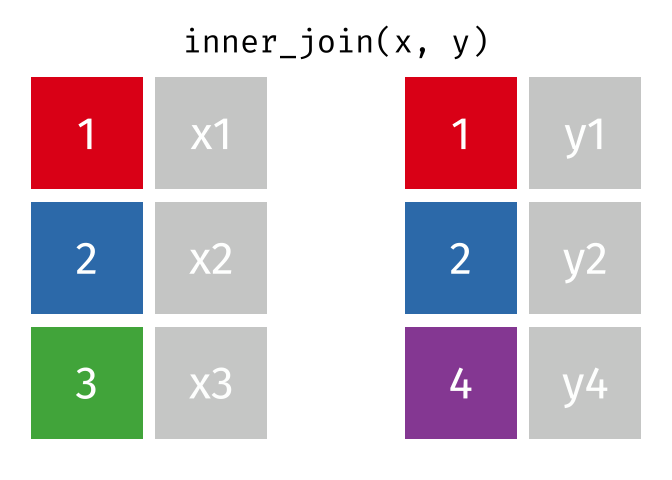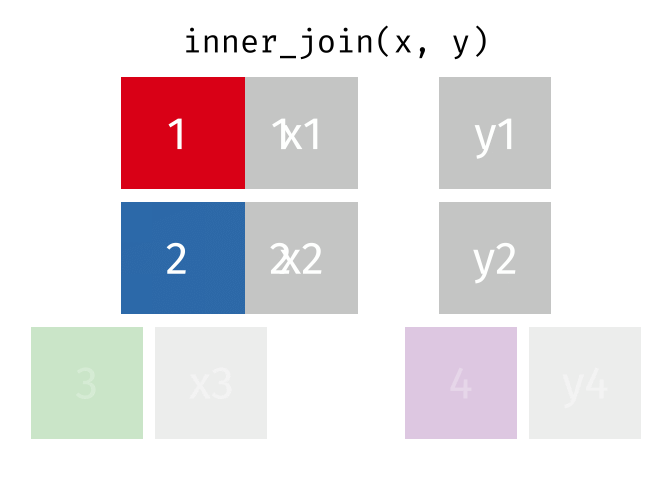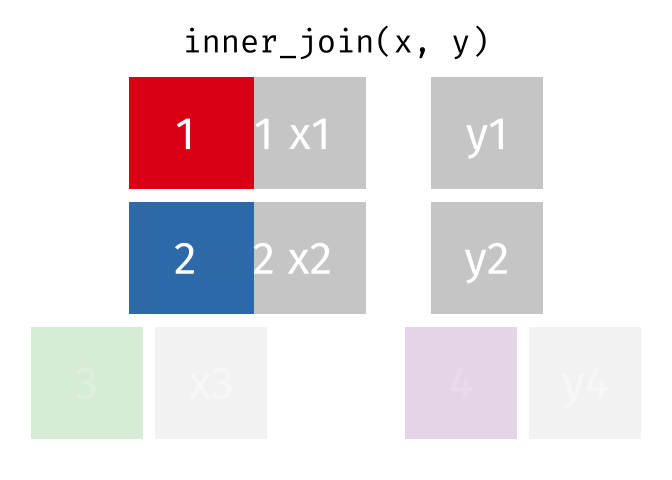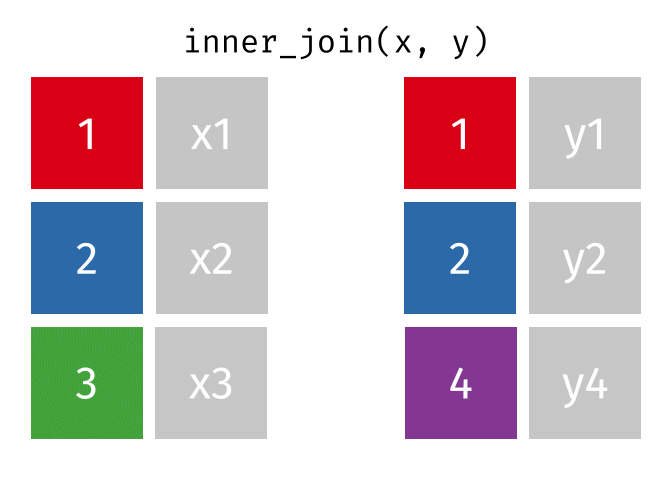
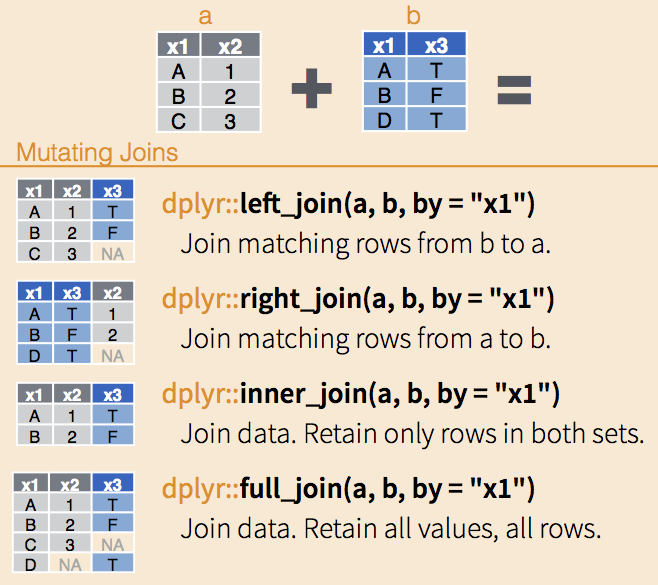
Inner-Join
- Merge columns from
xandyfor which there are matching rows- Rows in
xwith no match iny(3) will be dropped - Rows in
ywith no match inx(4) will be dropped
- Rows in
Left-Join
- Start with all rows from
xand add all columns fromy- Rows in
xwith no match iny(3) will haveNAs - Rows in
ywith no match inx(4) will be dropped
- Rows in
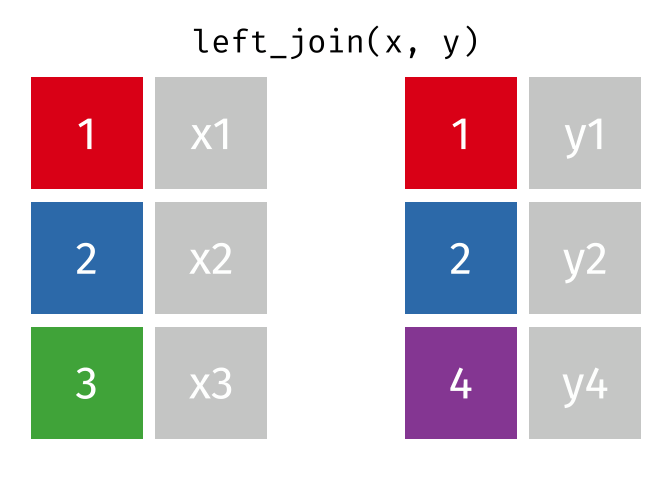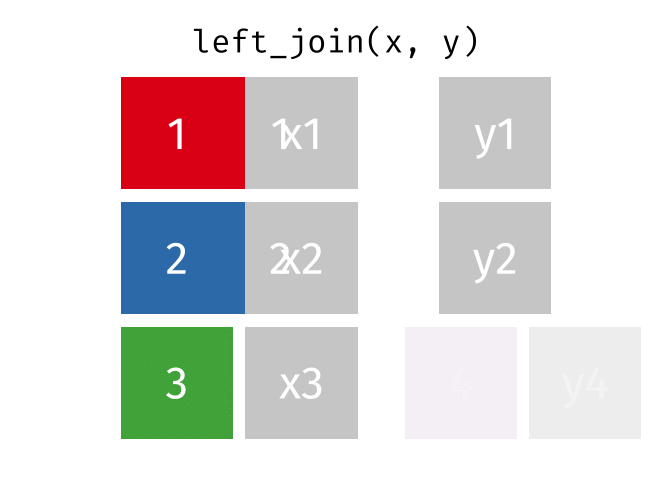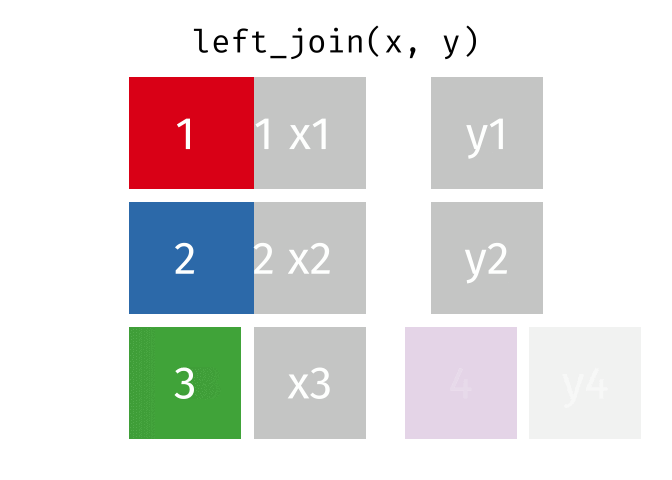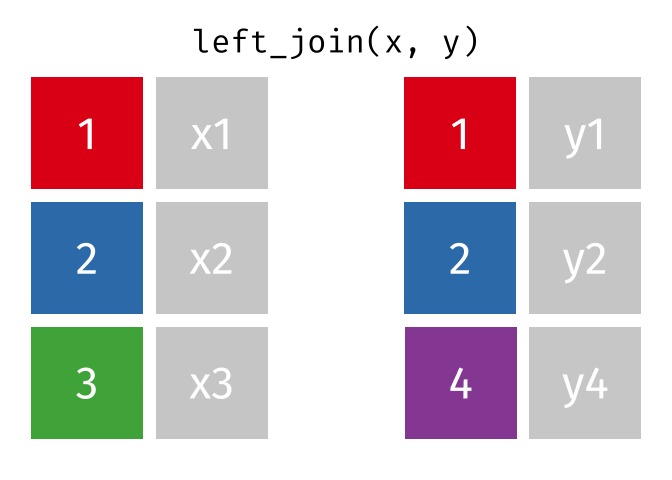
Right-Join
- Start with all rows from
yand add all columns fromx- Rows in
ywith no match inx(4) will haveNAs - Rows in
xwith no match iny(3) will be dropped
- Rows in

Full-Join
- All rows and all columns from
xandy- Rows that do not match (3 and 4) will have
NAs
- Rows that do not match (3 and 4) will have

References
tibblereadrand importing datadplyrand data wranglingtidyrand tidying or reshaping data- joining data