class: center, middle, inverse, title-slide # 4.1 — Panel Data and Fixed Effects ## ECON 480 • Econometrics • Fall 2020 ### Ryan Safner<br> Assistant Professor of Economics <br> <a href="mailto:safner@hood.edu"><i class="fa fa-paper-plane fa-fw"></i>safner@hood.edu</a> <br> <a href="https://github.com/ryansafner/metricsF20"><i class="fa fa-github fa-fw"></i>ryansafner/metricsF20</a><br> <a href="https://metricsF20.classes.ryansafner.com"> <i class="fa fa-globe fa-fw"></i>metricsF20.classes.ryansafner.com</a><br> --- # Types of Data I .pull-left[ .smallest[ - .red[**Cross-sectional data**]: compare different individual `\(i\)`’s at same time `\(\bar{t}\)` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["year"],"name":[2],"type":["fctr"],"align":["left"]},{"label":["deaths"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["cell_plans"],"name":[4],"type":["dbl"],"align":["right"]}],"data":[{"1":"Alabama","2":"2012","3":"13.316056","4":"9433.800"},{"1":"Alaska","2":"2012","3":"12.311976","4":"8872.799"},{"1":"Arizona","2":"2012","3":"13.720419","4":"8810.889"},{"1":"Arkansas","2":"2012","3":"16.466730","4":"10047.027"},{"1":"California","2":"2012","3":"8.756507","4":"9362.424"},{"1":"Colorado","2":"2012","3":"10.092204","4":"9403.225"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] -- .pull-right[ .smallest[ - .blue[**Time-series data**]: track same individual `\(\bar{i}\)` over different times `\(t\)` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["year"],"name":[2],"type":["fctr"],"align":["left"]},{"label":["deaths"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["cell_plans"],"name":[4],"type":["dbl"],"align":["right"]}],"data":[{"1":"Maryland","2":"2007","3":"10.866679","4":"8942.137"},{"1":"Maryland","2":"2008","3":"10.740963","4":"9290.689"},{"1":"Maryland","2":"2009","3":"9.892754","4":"9339.452"},{"1":"Maryland","2":"2010","3":"8.783883","4":"9630.120"},{"1":"Maryland","2":"2011","3":"8.626745","4":"10335.795"},{"1":"Maryland","2":"2012","3":"8.941916","4":"10393.295"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # Types of Data I .pull-left[ .smallest[ - .red[**Cross-sectional data**]: compare different individual `\(i\)`’s at same time `\(\bar{t}\)` ] <img src="4.1-slides_files/figure-html/unnamed-chunk-4-1.png" width="504" /> ] .pull-right[ .smallest[ - .blue[**Time-series data**]: track same individual `\(\bar{i}\)` over different times `\(t\)` ] <img src="4.1-slides_files/figure-html/unnamed-chunk-5-1.png" width="504" /> ] -- - .purple[**Panel data**]: combines these dimensions: compare all individual `\(i\)`’s over all time `\(t\)`’s --- # Panel Data I <img src="4.1-slides_files/figure-html/unnamed-chunk-6-1.png" width="1008" style="display: block; margin: auto;" /> --- # Panel Data II .pull-left[ .quitesmall[ <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["year"],"name":[2],"type":["fctr"],"align":["left"]},{"label":["deaths"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["cell_plans"],"name":[4],"type":["dbl"],"align":["right"]}],"data":[{"1":"Alabama","2":"2007","3":"18.075232","4":"8135.525"},{"1":"Alabama","2":"2008","3":"16.289227","4":"8494.391"},{"1":"Alabama","2":"2009","3":"13.833678","4":"8979.108"},{"1":"Alabama","2":"2010","3":"13.434084","4":"9054.894"},{"1":"Alabama","2":"2011","3":"13.771989","4":"9340.501"},{"1":"Alabama","2":"2012","3":"13.316056","4":"9433.800"},{"1":"Alaska","2":"2007","3":"16.301184","4":"6730.282"},{"1":"Alaska","2":"2008","3":"12.744090","4":"5580.707"},{"1":"Alaska","2":"2009","3":"12.973849","4":"8389.730"},{"1":"Alaska","2":"2010","3":"11.670893","4":"8560.595"},{"1":"Alaska","2":"2011","3":"15.675724","4":"8772.439"},{"1":"Alaska","2":"2012","3":"12.311976","4":"8872.799"},{"1":"Arizona","2":"2007","3":"16.930578","4":"7572.465"},{"1":"Arizona","2":"2008","3":"15.204128","4":"7665.941"},{"1":"Arizona","2":"2009","3":"13.094697","4":"7733.735"},{"1":"Arizona","2":"2010","3":"12.701025","4":"8268.126"},{"1":"Arizona","2":"2011","3":"13.848103","4":"8533.738"},{"1":"Arizona","2":"2012","3":"13.720419","4":"8810.889"},{"1":"Arkansas","2":"2007","3":"19.595430","4":"8071.125"},{"1":"Arkansas","2":"2008","3":"18.092453","4":"8860.436"},{"1":"Arkansas","2":"2009","3":"17.644802","4":"8717.922"},{"1":"Arkansas","2":"2010","3":"16.803751","4":"9166.925"},{"1":"Arkansas","2":"2011","3":"16.660118","4":"10745.481"},{"1":"Arkansas","2":"2012","3":"16.466730","4":"10047.027"},{"1":"California","2":"2007","3":"12.104340","4":"8821.933"},{"1":"California","2":"2008","3":"10.492352","4":"8754.059"},{"1":"California","2":"2009","3":"9.495017","4":"8911.396"},{"1":"California","2":"2010","3":"8.409493","4":"9083.331"},{"1":"California","2":"2011","3":"8.700562","4":"9244.424"},{"1":"California","2":"2012","3":"8.756507","4":"9362.424"},{"1":"Colorado","2":"2007","3":"11.372734","4":"8162.065"},{"1":"Colorado","2":"2008","3":"11.450063","4":"8727.682"},{"1":"Colorado","2":"2009","3":"10.058328","4":"8961.644"},{"1":"Colorado","2":"2010","3":"9.544113","4":"9319.581"},{"1":"Colorado","2":"2011","3":"9.590985","4":"9316.377"},{"1":"Colorado","2":"2012","3":"10.092204","4":"9403.225"},{"1":"Connecticut","2":"2007","3":"8.641937","4":"8234.567"},{"1":"Connecticut","2":"2008","3":"8.318367","4":"8654.047"},{"1":"Connecticut","2":"2009","3":"7.097390","4":"8876.477"},{"1":"Connecticut","2":"2010","3":"10.193512","4":"9037.248"},{"1":"Connecticut","2":"2011","3":"7.051904","4":"9364.067"},{"1":"Connecticut","2":"2012","3":"7.547323","4":"9519.971"},{"1":"Delaware","2":"2007","3":"12.337868","4":"8684.450"},{"1":"Delaware","2":"2008","3":"13.480392","4":"8910.859"},{"1":"Delaware","2":"2009","3":"12.775331","4":"9072.195"},{"1":"Delaware","2":"2010","3":"11.287853","4":"9477.312"},{"1":"Delaware","2":"2011","3":"10.965674","4":"9833.156"},{"1":"Delaware","2":"2012","3":"12.410543","4":"9846.341"},{"1":"District of Columbia","2":"2007","3":"12.191743","4":"15910.466"},{"1":"District of Columbia","2":"2008","3":"9.415674","4":"18518.738"},{"1":"District of Columbia","2":"2009","3":"8.037694","4":"19727.945"},{"1":"District of Columbia","2":"2010","3":"6.683713","4":"20757.059"},{"1":"District of Columbia","2":"2011","3":"7.567020","4":"21812.439"},{"1":"District of Columbia","2":"2012","3":"4.199528","4":"22140.584"},{"1":"Florida","2":"2007","3":"15.592783","4":"8550.103"},{"1":"Florida","2":"2008","3":"14.993757","4":"8815.855"},{"1":"Florida","2":"2009","3":"13.025808","4":"9032.273"},{"1":"Florida","2":"2010","3":"12.490121","4":"9175.425"},{"1":"Florida","2":"2011","3":"12.499025","4":"9388.934"},{"1":"Florida","2":"2012","3":"12.666312","4":"9508.961"},{"1":"Georgia","2":"2007","3":"14.581352","4":"8319.757"},{"1":"Georgia","2":"2008","3":"13.690088","4":"8592.009"},{"1":"Georgia","2":"2009","3":"11.752000","4":"9017.000"},{"1":"Georgia","2":"2010","3":"11.134734","4":"9355.207"},{"1":"Georgia","2":"2011","3":"11.276722","4":"9829.642"},{"1":"Georgia","2":"2012","3":"11.089559","4":"10135.137"},{"1":"Hawaii","2":"2007","3":"13.339778","4":"8539.896"},{"1":"Hawaii","2":"2008","3":"10.410585","4":"9191.134"},{"1":"Hawaii","2":"2009","3":"10.929510","4":"9388.671"},{"1":"Hawaii","2":"2010","3":"11.306049","4":"9203.846"},{"1":"Hawaii","2":"2011","3":"9.934058","4":"9419.483"},{"1":"Hawaii","2":"2012","3":"12.537733","4":"9617.091"},{"1":"Idaho","2":"2007","3":"15.967558","4":"7242.888"},{"1":"Idaho","2":"2008","3":"15.212117","4":"7658.405"},{"1":"Idaho","2":"2009","3":"14.551542","4":"7898.817"},{"1":"Idaho","2":"2010","3":"13.226838","4":"8146.304"},{"1":"Idaho","2":"2011","3":"10.479024","4":"8334.464"},{"1":"Idaho","2":"2012","3":"11.278261","4":"8541.556"},{"1":"Illinois","2":"2007","3":"11.620442","4":"8037.317"},{"1":"Illinois","2":"2008","3":"9.832294","4":"8463.315"},{"1":"Illinois","2":"2009","3":"8.606844","4":"8925.356"},{"1":"Illinois","2":"2010","3":"8.762821","4":"9397.043"},{"1":"Illinois","2":"2011","3":"8.892418","4":"9866.926"},{"1":"Illinois","2":"2012","3":"9.141466","4":"9987.375"},{"1":"Indiana","2":"2007","3":"12.563306","4":"7367.671"},{"1":"Indiana","2":"2008","3":"11.469151","4":"7771.933"},{"1":"Indiana","2":"2009","3":"9.043692","4":"8103.547"},{"1":"Indiana","2":"2010","3":"9.952415","4":"8343.870"},{"1":"Indiana","2":"2011","3":"9.805815","4":"8551.583"},{"1":"Indiana","2":"2012","3":"9.870433","4":"8850.703"},{"1":"Iowa","2":"2007","3":"14.238633","4":"7248.884"},{"1":"Iowa","2":"2008","3":"13.414516","4":"7723.422"},{"1":"Iowa","2":"2009","3":"11.974892","4":"8085.494"},{"1":"Iowa","2":"2010","3":"12.424887","4":"8094.920"},{"1":"Iowa","2":"2011","3":"11.511045","4":"8356.439"},{"1":"Iowa","2":"2012","3":"11.552008","4":"9033.285"},{"1":"Kansas","2":"2007","3":"13.844516","4":"8144.821"},{"1":"Kansas","2":"2008","3":"12.951189","4":"8639.844"},{"1":"Kansas","2":"2009","3":"13.086194","4":"8748.568"},{"1":"Kansas","2":"2010","3":"14.414881","4":"8972.640"},{"1":"Kansas","2":"2011","3":"12.857560","4":"9232.951"},{"1":"Kansas","2":"2012","3":"13.247210","4":"9341.957"},{"1":"Kentucky","2":"2007","3":"17.976406","4":"7759.095"},{"1":"Kentucky","2":"2008","3":"17.377035","4":"8069.342"},{"1":"Kentucky","2":"2009","3":"16.703621","4":"8416.562"},{"1":"Kentucky","2":"2010","3":"15.831109","4":"8586.506"},{"1":"Kentucky","2":"2011","3":"15.001671","4":"8724.397"},{"1":"Kentucky","2":"2012","3":"15.757031","4":"9076.766"},{"1":"Louisiana","2":"2007","3":"21.707510","4":"8769.674"},{"1":"Louisiana","2":"2008","3":"20.225765","4":"9095.864"},{"1":"Louisiana","2":"2009","3":"18.300158","4":"8888.986"},{"1":"Louisiana","2":"2010","3":"15.625450","4":"9573.448"},{"1":"Louisiana","2":"2011","3":"14.512162","4":"11832.118"},{"1":"Louisiana","2":"2012","3":"15.398054","4":"10643.446"},{"1":"Maine","2":"2007","3":"12.171599","4":"7143.904"},{"1":"Maine","2":"2008","3":"10.646336","4":"7687.306"},{"1":"Maine","2":"2009","3":"10.972327","4":"8078.580"},{"1":"Maine","2":"2010","3":"11.065762","4":"8461.556"},{"1":"Maine","2":"2011","3":"9.545046","4":"8854.168"},{"1":"Maine","2":"2012","3":"11.550250","4":"9058.135"},{"1":"Maryland","2":"2007","3":"10.866679","4":"8942.137"},{"1":"Maryland","2":"2008","3":"10.740963","4":"9290.689"},{"1":"Maryland","2":"2009","3":"9.892754","4":"9339.452"},{"1":"Maryland","2":"2010","3":"8.783883","4":"9630.120"},{"1":"Maryland","2":"2011","3":"8.626745","4":"10335.795"},{"1":"Maryland","2":"2012","3":"8.941916","4":"10393.295"},{"1":"Massachusetts","2":"2007","3":"7.572043","4":"8480.942"},{"1":"Massachusetts","2":"2008","3":"6.659939","4":"8847.383"},{"1":"Massachusetts","2":"2009","3":"6.093556","4":"9359.094"},{"1":"Massachusetts","2":"2010","3":"5.776095","4":"9646.240"},{"1":"Massachusetts","2":"2011","3":"6.150565","4":"9900.516"},{"1":"Massachusetts","2":"2012","3":"6.238859","4":"10085.547"},{"1":"Michigan","2":"2007","3":"10.400138","4":"7553.748"},{"1":"Michigan","2":"2008","3":"9.624355","4":"8024.254"},{"1":"Michigan","2":"2009","3":"9.000816","4":"8602.041"},{"1":"Michigan","2":"2010","3":"9.654868","4":"8965.320"},{"1":"Michigan","2":"2011","3":"9.382163","4":"9354.825"},{"1":"Michigan","2":"2012","3":"9.920888","4":"9711.272"},{"1":"Minnesota","2":"2007","3":"8.806108","4":"7788.179"},{"1":"Minnesota","2":"2008","3":"7.862747","4":"8323.128"},{"1":"Minnesota","2":"2009","3":"7.401740","4":"8429.205"},{"1":"Minnesota","2":"2010","3":"7.257423","4":"8868.903"},{"1":"Minnesota","2":"2011","3":"6.492050","4":"9231.297"},{"1":"Minnesota","2":"2012","3":"6.931245","4":"9581.459"},{"1":"Mississippi","2":"2007","3":"20.398273","4":"7523.679"},{"1":"Mississippi","2":"2008","3":"17.913111","4":"7867.644"},{"1":"Mississippi","2":"2009","3":"17.315161","4":"7943.778"},{"1":"Mississippi","2":"2010","3":"16.088942","4":"8222.972"},{"1":"Mississippi","2":"2011","3":"16.215916","4":"8917.204"},{"1":"Mississippi","2":"2012","3":"15.051544","4":"8898.043"},{"1":"Missouri","2":"2007","3":"14.345418","4":"7951.123"},{"1":"Missouri","2":"2008","3":"14.061195","4":"8356.444"},{"1":"Missouri","2":"2009","3":"12.724085","4":"8566.065"},{"1":"Missouri","2":"2010","3":"11.557350","4":"8864.693"},{"1":"Missouri","2":"2011","3":"11.397134","4":"9364.984"},{"1":"Missouri","2":"2012","3":"12.057746","4":"9412.174"},{"1":"Montana","2":"2007","3":"24.498098","4":"7245.310"},{"1":"Montana","2":"2008","3":"21.180170","4":"7731.746"},{"1":"Montana","2":"2009","3":"20.070839","4":"8225.733"},{"1":"Montana","2":"2010","3":"16.890373","4":"8550.507"},{"1":"Montana","2":"2011","3":"17.925146","4":"8635.553"},{"1":"Montana","2":"2012","3":"17.248453","4":"8834.581"},{"1":"Nebraska","2":"2007","3":"13.169402","4":"7815.974"},{"1":"Nebraska","2":"2008","3":"10.850286","4":"8388.321"},{"1":"Nebraska","2":"2009","3":"11.519190","4":"8432.506"},{"1":"Nebraska","2":"2010","3":"9.774693","4":"8339.078"},{"1":"Nebraska","2":"2011","3":"9.479756","4":"8938.258"},{"1":"Nebraska","2":"2012","3":"10.997818","4":"9027.095"},{"1":"Nevada","2":"2007","3":"16.842772","4":"8447.085"},{"1":"Nevada","2":"2008","3":"15.591915","4":"8722.517"},{"1":"Nevada","2":"2009","3":"11.880317","4":"9053.814"},{"1":"Nevada","2":"2010","3":"11.575836","4":"9083.331"},{"1":"Nevada","2":"2011","3":"10.169779","4":"9396.612"},{"1":"Nevada","2":"2012","3":"10.683987","4":"9463.811"},{"1":"New Hampshire","2":"2007","3":"9.584664","4":"7766.973"},{"1":"New Hampshire","2":"2008","3":"10.659510","4":"8207.878"},{"1":"New Hampshire","2":"2009","3":"8.477560","4":"8493.290"},{"1":"New Hampshire","2":"2010","3":"9.797003","4":"8887.403"},{"1":"New Hampshire","2":"2011","3":"7.075733","4":"9133.709"},{"1":"New Hampshire","2":"2012","3":"8.376215","4":"9275.258"},{"1":"New Jersey","2":"2007","3":"9.507301","4":"8811.962"},{"1":"New Jersey","2":"2008","3":"8.013147","4":"9222.979"},{"1":"New Jersey","2":"2009","3":"7.983130","4":"9368.678"},{"1":"New Jersey","2":"2010","3":"7.613554","4":"9782.875"},{"1":"New Jersey","2":"2011","3":"8.578022","4":"10107.520"},{"1":"New Jersey","2":"2012","3":"7.935292","4":"10169.675"},{"1":"New Mexico","2":"2007","3":"15.381750","4":"7558.702"},{"1":"New Mexico","2":"2008","3":"13.927470","4":"7740.546"},{"1":"New Mexico","2":"2009","3":"13.877677","4":"8080.925"},{"1":"New Mexico","2":"2010","3":"13.690132","4":"8202.298"},{"1":"New Mexico","2":"2011","3":"13.762094","4":"8116.322"},{"1":"New Mexico","2":"2012","3":"14.279203","4":"8328.786"},{"1":"New York","2":"2007","3":"9.748642","4":"8495.818"},{"1":"New York","2":"2008","3":"9.180743","4":"8569.393"},{"1":"New York","2":"2009","3":"8.659760","4":"9662.536"},{"1":"New York","2":"2010","3":"9.142714","4":"10064.969"},{"1":"New York","2":"2011","3":"9.152429","4":"10378.523"},{"1":"New York","2":"2012","3":"9.109303","4":"10584.938"},{"1":"North Carolina","2":"2007","3":"16.168266","4":"8063.099"},{"1":"North Carolina","2":"2008","3":"14.088799","4":"8700.542"},{"1":"North Carolina","2":"2009","3":"12.808267","4":"8643.108"},{"1":"North Carolina","2":"2010","3":"12.882751","4":"8941.341"},{"1":"North Carolina","2":"2011","3":"11.823957","4":"9430.015"},{"1":"North Carolina","2":"2012","3":"12.310631","4":"9213.426"},{"1":"North Dakota","2":"2007","3":"14.150944","4":"8019.196"},{"1":"North Dakota","2":"2008","3":"13.299232","4":"9057.166"},{"1":"North Dakota","2":"2009","3":"17.169487","4":"9554.081"},{"1":"North Dakota","2":"2010","3":"12.708389","4":"9262.688"},{"1":"North Dakota","2":"2011","3":"16.209141","4":"9357.655"},{"1":"North Dakota","2":"2012","3":"16.862585","4":"9762.331"},{"1":"Ohio","2":"2007","3":"11.362096","4":"7935.001"},{"1":"Ohio","2":"2008","3":"10.987793","4":"8327.595"},{"1":"Ohio","2":"2009","3":"9.232191","4":"8714.641"},{"1":"Ohio","2":"2010","3":"9.657021","4":"9111.079"},{"1":"Ohio","2":"2011","3":"9.072243","4":"9633.648"},{"1":"Ohio","2":"2012","3":"9.963171","4":"10004.137"},{"1":"Oklahoma","2":"2007","3":"15.849660","4":"7527.681"},{"1":"Oklahoma","2":"2008","3":"15.443618","4":"7931.668"},{"1":"Oklahoma","2":"2009","3":"15.703134","4":"8345.425"},{"1":"Oklahoma","2":"2010","3":"13.990725","4":"8498.271"},{"1":"Oklahoma","2":"2011","3":"14.663876","4":"9051.808"},{"1":"Oklahoma","2":"2012","3":"14.789496","4":"10328.142"},{"1":"Oregon","2":"2007","3":"13.093525","4":"7799.960"},{"1":"Oregon","2":"2008","3":"12.429784","4":"8137.074"},{"1":"Oregon","2":"2009","3":"11.097374","4":"8456.063"},{"1":"Oregon","2":"2010","3":"9.385889","4":"8718.182"},{"1":"Oregon","2":"2011","3":"9.918079","4":"8840.715"},{"1":"Oregon","2":"2012","3":"10.128738","4":"9024.574"},{"1":"Pennsylvania","2":"2007","3":"13.716778","4":"7733.581"},{"1":"Pennsylvania","2":"2008","3":"13.611750","4":"8205.150"},{"1":"Pennsylvania","2":"2009","3":"12.169864","4":"8621.342"},{"1":"Pennsylvania","2":"2010","3":"13.196621","4":"8993.591"},{"1":"Pennsylvania","2":"2011","3":"12.963163","4":"9088.208"},{"1":"Pennsylvania","2":"2012","3":"13.247794","4":"9367.311"},{"1":"Rhode Island","2":"2007","3":"7.989810","4":"8016.396"},{"1":"Rhode Island","2":"2008","3":"7.939416","4":"8450.801"},{"1":"Rhode Island","2":"2009","3":"10.060606","4":"8478.849"},{"1":"Rhode Island","2":"2010","3":"7.970802","4":"8740.536"},{"1":"Rhode Island","2":"2011","3":"8.352921","4":"9102.998"},{"1":"Rhode Island","2":"2012","3":"8.197905","4":"9825.839"},{"1":"South Carolina","2":"2007","3":"20.857384","4":"7940.633"},{"1":"South Carolina","2":"2008","3":"18.549509","4":"7417.742"},{"1":"South Carolina","2":"2009","3":"18.196621","4":"8541.533"},{"1":"South Carolina","2":"2010","3":"16.488773","4":"8507.438"},{"1":"South Carolina","2":"2011","3":"16.991524","4":"8082.526"},{"1":"South Carolina","2":"2012","3":"17.599247","4":"9155.914"},{"1":"South Dakota","2":"2007","3":"16.213215","4":"7485.425"},{"1":"South Dakota","2":"2008","3":"13.242822","4":"7846.365"},{"1":"South Dakota","2":"2009","3":"14.822422","4":"8382.745"},{"1":"South Dakota","2":"2010","3":"15.790696","4":"8941.512"},{"1":"South Dakota","2":"2011","3":"12.330527","4":"8785.533"},{"1":"South Dakota","2":"2012","3":"14.593781","4":"8999.776"},{"1":"Tennessee","2":"2007","3":"16.999395","4":"8520.772"},{"1":"Tennessee","2":"2008","3":"14.898732","4":"8878.680"},{"1":"Tennessee","2":"2009","3":"14.083103","4":"9392.887"},{"1":"Tennessee","2":"2010","3":"14.636814","4":"9758.742"},{"1":"Tennessee","2":"2011","3":"13.370816","4":"9955.722"},{"1":"Tennessee","2":"2012","3":"14.248202","4":"10042.992"},{"1":"Texas","2":"2007","3":"13.814322","4":"8231.546"},{"1":"Texas","2":"2008","3":"14.368134","4":"8635.682"},{"1":"Texas","2":"2009","3":"13.353091","4":"8816.372"},{"1":"Texas","2":"2010","3":"12.811095","4":"9158.674"},{"1":"Texas","2":"2011","3":"12.702162","4":"9250.748"},{"1":"Texas","2":"2012","3":"14.287167","4":"9422.007"},{"1":"Utah","2":"2007","3":"11.143411","4":"7450.866"},{"1":"Utah","2":"2008","3":"10.587511","4":"7655.977"},{"1":"Utah","2":"2009","3":"9.290283","4":"7778.574"},{"1":"Utah","2":"2010","3":"8.877112","4":"8144.333"},{"1":"Utah","2":"2011","3":"9.152750","4":"8263.460"},{"1":"Utah","2":"2012","3":"8.180087","4":"8436.980"},{"1":"Vermont","2":"2007","3":"8.578113","4":"6470.783"},{"1":"Vermont","2":"2008","3":"9.983588","4":"7001.787"},{"1":"Vermont","2":"2009","3":"9.678263","4":"7446.603"},{"1":"Vermont","2":"2010","3":"9.796406","4":"7750.811"},{"1":"Vermont","2":"2011","3":"7.701961","4":"8093.469"},{"1":"Vermont","2":"2012","3":"10.671238","4":"8274.615"},{"1":"Virginia","2":"2007","3":"12.512641","4":"8319.404"},{"1":"Virginia","2":"2008","3":"10.014828","4":"8824.716"},{"1":"Virginia","2":"2009","3":"9.354109","4":"9197.484"},{"1":"Virginia","2":"2010","3":"9.005652","4":"9492.535"},{"1":"Virginia","2":"2011","3":"9.435128","4":"9605.262"},{"1":"Virginia","2":"2012","3":"9.597490","4":"9650.780"},{"1":"Washington","2":"2007","3":"9.975588","4":"8181.282"},{"1":"Washington","2":"2008","3":"9.377587","4":"8587.277"},{"1":"Washington","2":"2009","3":"8.720776","4":"8727.235"},{"1":"Washington","2":"2010","3":"8.008331","4":"8955.260"},{"1":"Washington","2":"2011","3":"8.023939","4":"9150.754"},{"1":"Washington","2":"2012","3":"7.822134","4":"9314.179"},{"1":"West Virginia","2":"2007","3":"20.958958","4":"6473.385"},{"1":"West Virginia","2":"2008","3":"18.292095","4":"7137.078"},{"1":"West Virginia","2":"2009","3":"18.157707","4":"7698.746"},{"1":"West Virginia","2":"2010","3":"16.403658","4":"8095.007"},{"1":"West Virginia","2":"2011","3":"17.771332","4":"8893.134"},{"1":"West Virginia","2":"2012","3":"17.632570","4":"8612.638"},{"1":"Wisconsin","2":"2007","3":"12.707377","4":"6858.706"},{"1":"Wisconsin","2":"2008","3":"10.528697","4":"7578.225"},{"1":"Wisconsin","2":"2009","3":"9.646302","4":"8039.225"},{"1":"Wisconsin","2":"2010","3":"9.626346","4":"8317.235"},{"1":"Wisconsin","2":"2011","3":"9.939593","4":"8633.056"},{"1":"Wisconsin","2":"2012","3":"10.408328","4":"8796.105"},{"1":"Wyoming","2":"2007","3":"16.015375","4":"8434.864"},{"1":"Wyoming","2":"2008","3":"16.830740","4":"9086.335"},{"1":"Wyoming","2":"2009","3":"14.005016","4":"9498.962"},{"1":"Wyoming","2":"2010","3":"16.554895","4":"9332.430"},{"1":"Wyoming","2":"2011","3":"14.602637","4":"9363.593"},{"1":"Wyoming","2":"2012","3":"13.267186","4":"9455.043"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] .pull-right[ - .purple[**Panel**] or .purple[**Longitudinal**] data contains - .blue[repeated observations] `\((t)\)` - on .red[multiple individuals] `\((i)\)` ] --- # Panel Data II .pull-left[ .quitesmall[ <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["year"],"name":[2],"type":["fctr"],"align":["left"]},{"label":["deaths"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["cell_plans"],"name":[4],"type":["dbl"],"align":["right"]}],"data":[{"1":"Alabama","2":"2007","3":"18.075232","4":"8135.525"},{"1":"Alabama","2":"2008","3":"16.289227","4":"8494.391"},{"1":"Alabama","2":"2009","3":"13.833678","4":"8979.108"},{"1":"Alabama","2":"2010","3":"13.434084","4":"9054.894"},{"1":"Alabama","2":"2011","3":"13.771989","4":"9340.501"},{"1":"Alabama","2":"2012","3":"13.316056","4":"9433.800"},{"1":"Alaska","2":"2007","3":"16.301184","4":"6730.282"},{"1":"Alaska","2":"2008","3":"12.744090","4":"5580.707"},{"1":"Alaska","2":"2009","3":"12.973849","4":"8389.730"},{"1":"Alaska","2":"2010","3":"11.670893","4":"8560.595"},{"1":"Alaska","2":"2011","3":"15.675724","4":"8772.439"},{"1":"Alaska","2":"2012","3":"12.311976","4":"8872.799"},{"1":"Arizona","2":"2007","3":"16.930578","4":"7572.465"},{"1":"Arizona","2":"2008","3":"15.204128","4":"7665.941"},{"1":"Arizona","2":"2009","3":"13.094697","4":"7733.735"},{"1":"Arizona","2":"2010","3":"12.701025","4":"8268.126"},{"1":"Arizona","2":"2011","3":"13.848103","4":"8533.738"},{"1":"Arizona","2":"2012","3":"13.720419","4":"8810.889"},{"1":"Arkansas","2":"2007","3":"19.595430","4":"8071.125"},{"1":"Arkansas","2":"2008","3":"18.092453","4":"8860.436"},{"1":"Arkansas","2":"2009","3":"17.644802","4":"8717.922"},{"1":"Arkansas","2":"2010","3":"16.803751","4":"9166.925"},{"1":"Arkansas","2":"2011","3":"16.660118","4":"10745.481"},{"1":"Arkansas","2":"2012","3":"16.466730","4":"10047.027"},{"1":"California","2":"2007","3":"12.104340","4":"8821.933"},{"1":"California","2":"2008","3":"10.492352","4":"8754.059"},{"1":"California","2":"2009","3":"9.495017","4":"8911.396"},{"1":"California","2":"2010","3":"8.409493","4":"9083.331"},{"1":"California","2":"2011","3":"8.700562","4":"9244.424"},{"1":"California","2":"2012","3":"8.756507","4":"9362.424"},{"1":"Colorado","2":"2007","3":"11.372734","4":"8162.065"},{"1":"Colorado","2":"2008","3":"11.450063","4":"8727.682"},{"1":"Colorado","2":"2009","3":"10.058328","4":"8961.644"},{"1":"Colorado","2":"2010","3":"9.544113","4":"9319.581"},{"1":"Colorado","2":"2011","3":"9.590985","4":"9316.377"},{"1":"Colorado","2":"2012","3":"10.092204","4":"9403.225"},{"1":"Connecticut","2":"2007","3":"8.641937","4":"8234.567"},{"1":"Connecticut","2":"2008","3":"8.318367","4":"8654.047"},{"1":"Connecticut","2":"2009","3":"7.097390","4":"8876.477"},{"1":"Connecticut","2":"2010","3":"10.193512","4":"9037.248"},{"1":"Connecticut","2":"2011","3":"7.051904","4":"9364.067"},{"1":"Connecticut","2":"2012","3":"7.547323","4":"9519.971"},{"1":"Delaware","2":"2007","3":"12.337868","4":"8684.450"},{"1":"Delaware","2":"2008","3":"13.480392","4":"8910.859"},{"1":"Delaware","2":"2009","3":"12.775331","4":"9072.195"},{"1":"Delaware","2":"2010","3":"11.287853","4":"9477.312"},{"1":"Delaware","2":"2011","3":"10.965674","4":"9833.156"},{"1":"Delaware","2":"2012","3":"12.410543","4":"9846.341"},{"1":"District of Columbia","2":"2007","3":"12.191743","4":"15910.466"},{"1":"District of Columbia","2":"2008","3":"9.415674","4":"18518.738"},{"1":"District of Columbia","2":"2009","3":"8.037694","4":"19727.945"},{"1":"District of Columbia","2":"2010","3":"6.683713","4":"20757.059"},{"1":"District of Columbia","2":"2011","3":"7.567020","4":"21812.439"},{"1":"District of Columbia","2":"2012","3":"4.199528","4":"22140.584"},{"1":"Florida","2":"2007","3":"15.592783","4":"8550.103"},{"1":"Florida","2":"2008","3":"14.993757","4":"8815.855"},{"1":"Florida","2":"2009","3":"13.025808","4":"9032.273"},{"1":"Florida","2":"2010","3":"12.490121","4":"9175.425"},{"1":"Florida","2":"2011","3":"12.499025","4":"9388.934"},{"1":"Florida","2":"2012","3":"12.666312","4":"9508.961"},{"1":"Georgia","2":"2007","3":"14.581352","4":"8319.757"},{"1":"Georgia","2":"2008","3":"13.690088","4":"8592.009"},{"1":"Georgia","2":"2009","3":"11.752000","4":"9017.000"},{"1":"Georgia","2":"2010","3":"11.134734","4":"9355.207"},{"1":"Georgia","2":"2011","3":"11.276722","4":"9829.642"},{"1":"Georgia","2":"2012","3":"11.089559","4":"10135.137"},{"1":"Hawaii","2":"2007","3":"13.339778","4":"8539.896"},{"1":"Hawaii","2":"2008","3":"10.410585","4":"9191.134"},{"1":"Hawaii","2":"2009","3":"10.929510","4":"9388.671"},{"1":"Hawaii","2":"2010","3":"11.306049","4":"9203.846"},{"1":"Hawaii","2":"2011","3":"9.934058","4":"9419.483"},{"1":"Hawaii","2":"2012","3":"12.537733","4":"9617.091"},{"1":"Idaho","2":"2007","3":"15.967558","4":"7242.888"},{"1":"Idaho","2":"2008","3":"15.212117","4":"7658.405"},{"1":"Idaho","2":"2009","3":"14.551542","4":"7898.817"},{"1":"Idaho","2":"2010","3":"13.226838","4":"8146.304"},{"1":"Idaho","2":"2011","3":"10.479024","4":"8334.464"},{"1":"Idaho","2":"2012","3":"11.278261","4":"8541.556"},{"1":"Illinois","2":"2007","3":"11.620442","4":"8037.317"},{"1":"Illinois","2":"2008","3":"9.832294","4":"8463.315"},{"1":"Illinois","2":"2009","3":"8.606844","4":"8925.356"},{"1":"Illinois","2":"2010","3":"8.762821","4":"9397.043"},{"1":"Illinois","2":"2011","3":"8.892418","4":"9866.926"},{"1":"Illinois","2":"2012","3":"9.141466","4":"9987.375"},{"1":"Indiana","2":"2007","3":"12.563306","4":"7367.671"},{"1":"Indiana","2":"2008","3":"11.469151","4":"7771.933"},{"1":"Indiana","2":"2009","3":"9.043692","4":"8103.547"},{"1":"Indiana","2":"2010","3":"9.952415","4":"8343.870"},{"1":"Indiana","2":"2011","3":"9.805815","4":"8551.583"},{"1":"Indiana","2":"2012","3":"9.870433","4":"8850.703"},{"1":"Iowa","2":"2007","3":"14.238633","4":"7248.884"},{"1":"Iowa","2":"2008","3":"13.414516","4":"7723.422"},{"1":"Iowa","2":"2009","3":"11.974892","4":"8085.494"},{"1":"Iowa","2":"2010","3":"12.424887","4":"8094.920"},{"1":"Iowa","2":"2011","3":"11.511045","4":"8356.439"},{"1":"Iowa","2":"2012","3":"11.552008","4":"9033.285"},{"1":"Kansas","2":"2007","3":"13.844516","4":"8144.821"},{"1":"Kansas","2":"2008","3":"12.951189","4":"8639.844"},{"1":"Kansas","2":"2009","3":"13.086194","4":"8748.568"},{"1":"Kansas","2":"2010","3":"14.414881","4":"8972.640"},{"1":"Kansas","2":"2011","3":"12.857560","4":"9232.951"},{"1":"Kansas","2":"2012","3":"13.247210","4":"9341.957"},{"1":"Kentucky","2":"2007","3":"17.976406","4":"7759.095"},{"1":"Kentucky","2":"2008","3":"17.377035","4":"8069.342"},{"1":"Kentucky","2":"2009","3":"16.703621","4":"8416.562"},{"1":"Kentucky","2":"2010","3":"15.831109","4":"8586.506"},{"1":"Kentucky","2":"2011","3":"15.001671","4":"8724.397"},{"1":"Kentucky","2":"2012","3":"15.757031","4":"9076.766"},{"1":"Louisiana","2":"2007","3":"21.707510","4":"8769.674"},{"1":"Louisiana","2":"2008","3":"20.225765","4":"9095.864"},{"1":"Louisiana","2":"2009","3":"18.300158","4":"8888.986"},{"1":"Louisiana","2":"2010","3":"15.625450","4":"9573.448"},{"1":"Louisiana","2":"2011","3":"14.512162","4":"11832.118"},{"1":"Louisiana","2":"2012","3":"15.398054","4":"10643.446"},{"1":"Maine","2":"2007","3":"12.171599","4":"7143.904"},{"1":"Maine","2":"2008","3":"10.646336","4":"7687.306"},{"1":"Maine","2":"2009","3":"10.972327","4":"8078.580"},{"1":"Maine","2":"2010","3":"11.065762","4":"8461.556"},{"1":"Maine","2":"2011","3":"9.545046","4":"8854.168"},{"1":"Maine","2":"2012","3":"11.550250","4":"9058.135"},{"1":"Maryland","2":"2007","3":"10.866679","4":"8942.137"},{"1":"Maryland","2":"2008","3":"10.740963","4":"9290.689"},{"1":"Maryland","2":"2009","3":"9.892754","4":"9339.452"},{"1":"Maryland","2":"2010","3":"8.783883","4":"9630.120"},{"1":"Maryland","2":"2011","3":"8.626745","4":"10335.795"},{"1":"Maryland","2":"2012","3":"8.941916","4":"10393.295"},{"1":"Massachusetts","2":"2007","3":"7.572043","4":"8480.942"},{"1":"Massachusetts","2":"2008","3":"6.659939","4":"8847.383"},{"1":"Massachusetts","2":"2009","3":"6.093556","4":"9359.094"},{"1":"Massachusetts","2":"2010","3":"5.776095","4":"9646.240"},{"1":"Massachusetts","2":"2011","3":"6.150565","4":"9900.516"},{"1":"Massachusetts","2":"2012","3":"6.238859","4":"10085.547"},{"1":"Michigan","2":"2007","3":"10.400138","4":"7553.748"},{"1":"Michigan","2":"2008","3":"9.624355","4":"8024.254"},{"1":"Michigan","2":"2009","3":"9.000816","4":"8602.041"},{"1":"Michigan","2":"2010","3":"9.654868","4":"8965.320"},{"1":"Michigan","2":"2011","3":"9.382163","4":"9354.825"},{"1":"Michigan","2":"2012","3":"9.920888","4":"9711.272"},{"1":"Minnesota","2":"2007","3":"8.806108","4":"7788.179"},{"1":"Minnesota","2":"2008","3":"7.862747","4":"8323.128"},{"1":"Minnesota","2":"2009","3":"7.401740","4":"8429.205"},{"1":"Minnesota","2":"2010","3":"7.257423","4":"8868.903"},{"1":"Minnesota","2":"2011","3":"6.492050","4":"9231.297"},{"1":"Minnesota","2":"2012","3":"6.931245","4":"9581.459"},{"1":"Mississippi","2":"2007","3":"20.398273","4":"7523.679"},{"1":"Mississippi","2":"2008","3":"17.913111","4":"7867.644"},{"1":"Mississippi","2":"2009","3":"17.315161","4":"7943.778"},{"1":"Mississippi","2":"2010","3":"16.088942","4":"8222.972"},{"1":"Mississippi","2":"2011","3":"16.215916","4":"8917.204"},{"1":"Mississippi","2":"2012","3":"15.051544","4":"8898.043"},{"1":"Missouri","2":"2007","3":"14.345418","4":"7951.123"},{"1":"Missouri","2":"2008","3":"14.061195","4":"8356.444"},{"1":"Missouri","2":"2009","3":"12.724085","4":"8566.065"},{"1":"Missouri","2":"2010","3":"11.557350","4":"8864.693"},{"1":"Missouri","2":"2011","3":"11.397134","4":"9364.984"},{"1":"Missouri","2":"2012","3":"12.057746","4":"9412.174"},{"1":"Montana","2":"2007","3":"24.498098","4":"7245.310"},{"1":"Montana","2":"2008","3":"21.180170","4":"7731.746"},{"1":"Montana","2":"2009","3":"20.070839","4":"8225.733"},{"1":"Montana","2":"2010","3":"16.890373","4":"8550.507"},{"1":"Montana","2":"2011","3":"17.925146","4":"8635.553"},{"1":"Montana","2":"2012","3":"17.248453","4":"8834.581"},{"1":"Nebraska","2":"2007","3":"13.169402","4":"7815.974"},{"1":"Nebraska","2":"2008","3":"10.850286","4":"8388.321"},{"1":"Nebraska","2":"2009","3":"11.519190","4":"8432.506"},{"1":"Nebraska","2":"2010","3":"9.774693","4":"8339.078"},{"1":"Nebraska","2":"2011","3":"9.479756","4":"8938.258"},{"1":"Nebraska","2":"2012","3":"10.997818","4":"9027.095"},{"1":"Nevada","2":"2007","3":"16.842772","4":"8447.085"},{"1":"Nevada","2":"2008","3":"15.591915","4":"8722.517"},{"1":"Nevada","2":"2009","3":"11.880317","4":"9053.814"},{"1":"Nevada","2":"2010","3":"11.575836","4":"9083.331"},{"1":"Nevada","2":"2011","3":"10.169779","4":"9396.612"},{"1":"Nevada","2":"2012","3":"10.683987","4":"9463.811"},{"1":"New Hampshire","2":"2007","3":"9.584664","4":"7766.973"},{"1":"New Hampshire","2":"2008","3":"10.659510","4":"8207.878"},{"1":"New Hampshire","2":"2009","3":"8.477560","4":"8493.290"},{"1":"New Hampshire","2":"2010","3":"9.797003","4":"8887.403"},{"1":"New Hampshire","2":"2011","3":"7.075733","4":"9133.709"},{"1":"New Hampshire","2":"2012","3":"8.376215","4":"9275.258"},{"1":"New Jersey","2":"2007","3":"9.507301","4":"8811.962"},{"1":"New Jersey","2":"2008","3":"8.013147","4":"9222.979"},{"1":"New Jersey","2":"2009","3":"7.983130","4":"9368.678"},{"1":"New Jersey","2":"2010","3":"7.613554","4":"9782.875"},{"1":"New Jersey","2":"2011","3":"8.578022","4":"10107.520"},{"1":"New Jersey","2":"2012","3":"7.935292","4":"10169.675"},{"1":"New Mexico","2":"2007","3":"15.381750","4":"7558.702"},{"1":"New Mexico","2":"2008","3":"13.927470","4":"7740.546"},{"1":"New Mexico","2":"2009","3":"13.877677","4":"8080.925"},{"1":"New Mexico","2":"2010","3":"13.690132","4":"8202.298"},{"1":"New Mexico","2":"2011","3":"13.762094","4":"8116.322"},{"1":"New Mexico","2":"2012","3":"14.279203","4":"8328.786"},{"1":"New York","2":"2007","3":"9.748642","4":"8495.818"},{"1":"New York","2":"2008","3":"9.180743","4":"8569.393"},{"1":"New York","2":"2009","3":"8.659760","4":"9662.536"},{"1":"New York","2":"2010","3":"9.142714","4":"10064.969"},{"1":"New York","2":"2011","3":"9.152429","4":"10378.523"},{"1":"New York","2":"2012","3":"9.109303","4":"10584.938"},{"1":"North Carolina","2":"2007","3":"16.168266","4":"8063.099"},{"1":"North Carolina","2":"2008","3":"14.088799","4":"8700.542"},{"1":"North Carolina","2":"2009","3":"12.808267","4":"8643.108"},{"1":"North Carolina","2":"2010","3":"12.882751","4":"8941.341"},{"1":"North Carolina","2":"2011","3":"11.823957","4":"9430.015"},{"1":"North Carolina","2":"2012","3":"12.310631","4":"9213.426"},{"1":"North Dakota","2":"2007","3":"14.150944","4":"8019.196"},{"1":"North Dakota","2":"2008","3":"13.299232","4":"9057.166"},{"1":"North Dakota","2":"2009","3":"17.169487","4":"9554.081"},{"1":"North Dakota","2":"2010","3":"12.708389","4":"9262.688"},{"1":"North Dakota","2":"2011","3":"16.209141","4":"9357.655"},{"1":"North Dakota","2":"2012","3":"16.862585","4":"9762.331"},{"1":"Ohio","2":"2007","3":"11.362096","4":"7935.001"},{"1":"Ohio","2":"2008","3":"10.987793","4":"8327.595"},{"1":"Ohio","2":"2009","3":"9.232191","4":"8714.641"},{"1":"Ohio","2":"2010","3":"9.657021","4":"9111.079"},{"1":"Ohio","2":"2011","3":"9.072243","4":"9633.648"},{"1":"Ohio","2":"2012","3":"9.963171","4":"10004.137"},{"1":"Oklahoma","2":"2007","3":"15.849660","4":"7527.681"},{"1":"Oklahoma","2":"2008","3":"15.443618","4":"7931.668"},{"1":"Oklahoma","2":"2009","3":"15.703134","4":"8345.425"},{"1":"Oklahoma","2":"2010","3":"13.990725","4":"8498.271"},{"1":"Oklahoma","2":"2011","3":"14.663876","4":"9051.808"},{"1":"Oklahoma","2":"2012","3":"14.789496","4":"10328.142"},{"1":"Oregon","2":"2007","3":"13.093525","4":"7799.960"},{"1":"Oregon","2":"2008","3":"12.429784","4":"8137.074"},{"1":"Oregon","2":"2009","3":"11.097374","4":"8456.063"},{"1":"Oregon","2":"2010","3":"9.385889","4":"8718.182"},{"1":"Oregon","2":"2011","3":"9.918079","4":"8840.715"},{"1":"Oregon","2":"2012","3":"10.128738","4":"9024.574"},{"1":"Pennsylvania","2":"2007","3":"13.716778","4":"7733.581"},{"1":"Pennsylvania","2":"2008","3":"13.611750","4":"8205.150"},{"1":"Pennsylvania","2":"2009","3":"12.169864","4":"8621.342"},{"1":"Pennsylvania","2":"2010","3":"13.196621","4":"8993.591"},{"1":"Pennsylvania","2":"2011","3":"12.963163","4":"9088.208"},{"1":"Pennsylvania","2":"2012","3":"13.247794","4":"9367.311"},{"1":"Rhode Island","2":"2007","3":"7.989810","4":"8016.396"},{"1":"Rhode Island","2":"2008","3":"7.939416","4":"8450.801"},{"1":"Rhode Island","2":"2009","3":"10.060606","4":"8478.849"},{"1":"Rhode Island","2":"2010","3":"7.970802","4":"8740.536"},{"1":"Rhode Island","2":"2011","3":"8.352921","4":"9102.998"},{"1":"Rhode Island","2":"2012","3":"8.197905","4":"9825.839"},{"1":"South Carolina","2":"2007","3":"20.857384","4":"7940.633"},{"1":"South Carolina","2":"2008","3":"18.549509","4":"7417.742"},{"1":"South Carolina","2":"2009","3":"18.196621","4":"8541.533"},{"1":"South Carolina","2":"2010","3":"16.488773","4":"8507.438"},{"1":"South Carolina","2":"2011","3":"16.991524","4":"8082.526"},{"1":"South Carolina","2":"2012","3":"17.599247","4":"9155.914"},{"1":"South Dakota","2":"2007","3":"16.213215","4":"7485.425"},{"1":"South Dakota","2":"2008","3":"13.242822","4":"7846.365"},{"1":"South Dakota","2":"2009","3":"14.822422","4":"8382.745"},{"1":"South Dakota","2":"2010","3":"15.790696","4":"8941.512"},{"1":"South Dakota","2":"2011","3":"12.330527","4":"8785.533"},{"1":"South Dakota","2":"2012","3":"14.593781","4":"8999.776"},{"1":"Tennessee","2":"2007","3":"16.999395","4":"8520.772"},{"1":"Tennessee","2":"2008","3":"14.898732","4":"8878.680"},{"1":"Tennessee","2":"2009","3":"14.083103","4":"9392.887"},{"1":"Tennessee","2":"2010","3":"14.636814","4":"9758.742"},{"1":"Tennessee","2":"2011","3":"13.370816","4":"9955.722"},{"1":"Tennessee","2":"2012","3":"14.248202","4":"10042.992"},{"1":"Texas","2":"2007","3":"13.814322","4":"8231.546"},{"1":"Texas","2":"2008","3":"14.368134","4":"8635.682"},{"1":"Texas","2":"2009","3":"13.353091","4":"8816.372"},{"1":"Texas","2":"2010","3":"12.811095","4":"9158.674"},{"1":"Texas","2":"2011","3":"12.702162","4":"9250.748"},{"1":"Texas","2":"2012","3":"14.287167","4":"9422.007"},{"1":"Utah","2":"2007","3":"11.143411","4":"7450.866"},{"1":"Utah","2":"2008","3":"10.587511","4":"7655.977"},{"1":"Utah","2":"2009","3":"9.290283","4":"7778.574"},{"1":"Utah","2":"2010","3":"8.877112","4":"8144.333"},{"1":"Utah","2":"2011","3":"9.152750","4":"8263.460"},{"1":"Utah","2":"2012","3":"8.180087","4":"8436.980"},{"1":"Vermont","2":"2007","3":"8.578113","4":"6470.783"},{"1":"Vermont","2":"2008","3":"9.983588","4":"7001.787"},{"1":"Vermont","2":"2009","3":"9.678263","4":"7446.603"},{"1":"Vermont","2":"2010","3":"9.796406","4":"7750.811"},{"1":"Vermont","2":"2011","3":"7.701961","4":"8093.469"},{"1":"Vermont","2":"2012","3":"10.671238","4":"8274.615"},{"1":"Virginia","2":"2007","3":"12.512641","4":"8319.404"},{"1":"Virginia","2":"2008","3":"10.014828","4":"8824.716"},{"1":"Virginia","2":"2009","3":"9.354109","4":"9197.484"},{"1":"Virginia","2":"2010","3":"9.005652","4":"9492.535"},{"1":"Virginia","2":"2011","3":"9.435128","4":"9605.262"},{"1":"Virginia","2":"2012","3":"9.597490","4":"9650.780"},{"1":"Washington","2":"2007","3":"9.975588","4":"8181.282"},{"1":"Washington","2":"2008","3":"9.377587","4":"8587.277"},{"1":"Washington","2":"2009","3":"8.720776","4":"8727.235"},{"1":"Washington","2":"2010","3":"8.008331","4":"8955.260"},{"1":"Washington","2":"2011","3":"8.023939","4":"9150.754"},{"1":"Washington","2":"2012","3":"7.822134","4":"9314.179"},{"1":"West Virginia","2":"2007","3":"20.958958","4":"6473.385"},{"1":"West Virginia","2":"2008","3":"18.292095","4":"7137.078"},{"1":"West Virginia","2":"2009","3":"18.157707","4":"7698.746"},{"1":"West Virginia","2":"2010","3":"16.403658","4":"8095.007"},{"1":"West Virginia","2":"2011","3":"17.771332","4":"8893.134"},{"1":"West Virginia","2":"2012","3":"17.632570","4":"8612.638"},{"1":"Wisconsin","2":"2007","3":"12.707377","4":"6858.706"},{"1":"Wisconsin","2":"2008","3":"10.528697","4":"7578.225"},{"1":"Wisconsin","2":"2009","3":"9.646302","4":"8039.225"},{"1":"Wisconsin","2":"2010","3":"9.626346","4":"8317.235"},{"1":"Wisconsin","2":"2011","3":"9.939593","4":"8633.056"},{"1":"Wisconsin","2":"2012","3":"10.408328","4":"8796.105"},{"1":"Wyoming","2":"2007","3":"16.015375","4":"8434.864"},{"1":"Wyoming","2":"2008","3":"16.830740","4":"9086.335"},{"1":"Wyoming","2":"2009","3":"14.005016","4":"9498.962"},{"1":"Wyoming","2":"2010","3":"16.554895","4":"9332.430"},{"1":"Wyoming","2":"2011","3":"14.602637","4":"9363.593"},{"1":"Wyoming","2":"2012","3":"13.267186","4":"9455.043"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] .pull-right[ - .purple[**Panel**] or .purple[**Longitudinal**] data contains - .blue[repeated observations] `\((t)\)` - on .red[multiple individuals] `\((i)\)` - Thus, our regression equation looks like: $$ `\begin{align} \hat{Y_{\color{red}{i}\color{blue}{t}}} = \beta_0 + \beta_1 X_{\color{red}{i}\color{blue}{t}} + u_{\color{red}{i}\color{blue}{t}} \end{align}` $$ > for .red[individual `\\(i\\)`] in .blue[time `\\(t\\)`]. ] --- # Panel Data: Our Motivating Example .pull-left[ .quitesmall[ <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["year"],"name":[2],"type":["fctr"],"align":["left"]},{"label":["deaths"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["cell_plans"],"name":[4],"type":["dbl"],"align":["right"]}],"data":[{"1":"Alabama","2":"2007","3":"18.075232","4":"8135.525"},{"1":"Alabama","2":"2008","3":"16.289227","4":"8494.391"},{"1":"Alabama","2":"2009","3":"13.833678","4":"8979.108"},{"1":"Alabama","2":"2010","3":"13.434084","4":"9054.894"},{"1":"Alabama","2":"2011","3":"13.771989","4":"9340.501"},{"1":"Alabama","2":"2012","3":"13.316056","4":"9433.800"},{"1":"Alaska","2":"2007","3":"16.301184","4":"6730.282"},{"1":"Alaska","2":"2008","3":"12.744090","4":"5580.707"},{"1":"Alaska","2":"2009","3":"12.973849","4":"8389.730"},{"1":"Alaska","2":"2010","3":"11.670893","4":"8560.595"},{"1":"Alaska","2":"2011","3":"15.675724","4":"8772.439"},{"1":"Alaska","2":"2012","3":"12.311976","4":"8872.799"},{"1":"Arizona","2":"2007","3":"16.930578","4":"7572.465"},{"1":"Arizona","2":"2008","3":"15.204128","4":"7665.941"},{"1":"Arizona","2":"2009","3":"13.094697","4":"7733.735"},{"1":"Arizona","2":"2010","3":"12.701025","4":"8268.126"},{"1":"Arizona","2":"2011","3":"13.848103","4":"8533.738"},{"1":"Arizona","2":"2012","3":"13.720419","4":"8810.889"},{"1":"Arkansas","2":"2007","3":"19.595430","4":"8071.125"},{"1":"Arkansas","2":"2008","3":"18.092453","4":"8860.436"},{"1":"Arkansas","2":"2009","3":"17.644802","4":"8717.922"},{"1":"Arkansas","2":"2010","3":"16.803751","4":"9166.925"},{"1":"Arkansas","2":"2011","3":"16.660118","4":"10745.481"},{"1":"Arkansas","2":"2012","3":"16.466730","4":"10047.027"},{"1":"California","2":"2007","3":"12.104340","4":"8821.933"},{"1":"California","2":"2008","3":"10.492352","4":"8754.059"},{"1":"California","2":"2009","3":"9.495017","4":"8911.396"},{"1":"California","2":"2010","3":"8.409493","4":"9083.331"},{"1":"California","2":"2011","3":"8.700562","4":"9244.424"},{"1":"California","2":"2012","3":"8.756507","4":"9362.424"},{"1":"Colorado","2":"2007","3":"11.372734","4":"8162.065"},{"1":"Colorado","2":"2008","3":"11.450063","4":"8727.682"},{"1":"Colorado","2":"2009","3":"10.058328","4":"8961.644"},{"1":"Colorado","2":"2010","3":"9.544113","4":"9319.581"},{"1":"Colorado","2":"2011","3":"9.590985","4":"9316.377"},{"1":"Colorado","2":"2012","3":"10.092204","4":"9403.225"},{"1":"Connecticut","2":"2007","3":"8.641937","4":"8234.567"},{"1":"Connecticut","2":"2008","3":"8.318367","4":"8654.047"},{"1":"Connecticut","2":"2009","3":"7.097390","4":"8876.477"},{"1":"Connecticut","2":"2010","3":"10.193512","4":"9037.248"},{"1":"Connecticut","2":"2011","3":"7.051904","4":"9364.067"},{"1":"Connecticut","2":"2012","3":"7.547323","4":"9519.971"},{"1":"Delaware","2":"2007","3":"12.337868","4":"8684.450"},{"1":"Delaware","2":"2008","3":"13.480392","4":"8910.859"},{"1":"Delaware","2":"2009","3":"12.775331","4":"9072.195"},{"1":"Delaware","2":"2010","3":"11.287853","4":"9477.312"},{"1":"Delaware","2":"2011","3":"10.965674","4":"9833.156"},{"1":"Delaware","2":"2012","3":"12.410543","4":"9846.341"},{"1":"District of Columbia","2":"2007","3":"12.191743","4":"15910.466"},{"1":"District of Columbia","2":"2008","3":"9.415674","4":"18518.738"},{"1":"District of Columbia","2":"2009","3":"8.037694","4":"19727.945"},{"1":"District of Columbia","2":"2010","3":"6.683713","4":"20757.059"},{"1":"District of Columbia","2":"2011","3":"7.567020","4":"21812.439"},{"1":"District of Columbia","2":"2012","3":"4.199528","4":"22140.584"},{"1":"Florida","2":"2007","3":"15.592783","4":"8550.103"},{"1":"Florida","2":"2008","3":"14.993757","4":"8815.855"},{"1":"Florida","2":"2009","3":"13.025808","4":"9032.273"},{"1":"Florida","2":"2010","3":"12.490121","4":"9175.425"},{"1":"Florida","2":"2011","3":"12.499025","4":"9388.934"},{"1":"Florida","2":"2012","3":"12.666312","4":"9508.961"},{"1":"Georgia","2":"2007","3":"14.581352","4":"8319.757"},{"1":"Georgia","2":"2008","3":"13.690088","4":"8592.009"},{"1":"Georgia","2":"2009","3":"11.752000","4":"9017.000"},{"1":"Georgia","2":"2010","3":"11.134734","4":"9355.207"},{"1":"Georgia","2":"2011","3":"11.276722","4":"9829.642"},{"1":"Georgia","2":"2012","3":"11.089559","4":"10135.137"},{"1":"Hawaii","2":"2007","3":"13.339778","4":"8539.896"},{"1":"Hawaii","2":"2008","3":"10.410585","4":"9191.134"},{"1":"Hawaii","2":"2009","3":"10.929510","4":"9388.671"},{"1":"Hawaii","2":"2010","3":"11.306049","4":"9203.846"},{"1":"Hawaii","2":"2011","3":"9.934058","4":"9419.483"},{"1":"Hawaii","2":"2012","3":"12.537733","4":"9617.091"},{"1":"Idaho","2":"2007","3":"15.967558","4":"7242.888"},{"1":"Idaho","2":"2008","3":"15.212117","4":"7658.405"},{"1":"Idaho","2":"2009","3":"14.551542","4":"7898.817"},{"1":"Idaho","2":"2010","3":"13.226838","4":"8146.304"},{"1":"Idaho","2":"2011","3":"10.479024","4":"8334.464"},{"1":"Idaho","2":"2012","3":"11.278261","4":"8541.556"},{"1":"Illinois","2":"2007","3":"11.620442","4":"8037.317"},{"1":"Illinois","2":"2008","3":"9.832294","4":"8463.315"},{"1":"Illinois","2":"2009","3":"8.606844","4":"8925.356"},{"1":"Illinois","2":"2010","3":"8.762821","4":"9397.043"},{"1":"Illinois","2":"2011","3":"8.892418","4":"9866.926"},{"1":"Illinois","2":"2012","3":"9.141466","4":"9987.375"},{"1":"Indiana","2":"2007","3":"12.563306","4":"7367.671"},{"1":"Indiana","2":"2008","3":"11.469151","4":"7771.933"},{"1":"Indiana","2":"2009","3":"9.043692","4":"8103.547"},{"1":"Indiana","2":"2010","3":"9.952415","4":"8343.870"},{"1":"Indiana","2":"2011","3":"9.805815","4":"8551.583"},{"1":"Indiana","2":"2012","3":"9.870433","4":"8850.703"},{"1":"Iowa","2":"2007","3":"14.238633","4":"7248.884"},{"1":"Iowa","2":"2008","3":"13.414516","4":"7723.422"},{"1":"Iowa","2":"2009","3":"11.974892","4":"8085.494"},{"1":"Iowa","2":"2010","3":"12.424887","4":"8094.920"},{"1":"Iowa","2":"2011","3":"11.511045","4":"8356.439"},{"1":"Iowa","2":"2012","3":"11.552008","4":"9033.285"},{"1":"Kansas","2":"2007","3":"13.844516","4":"8144.821"},{"1":"Kansas","2":"2008","3":"12.951189","4":"8639.844"},{"1":"Kansas","2":"2009","3":"13.086194","4":"8748.568"},{"1":"Kansas","2":"2010","3":"14.414881","4":"8972.640"},{"1":"Kansas","2":"2011","3":"12.857560","4":"9232.951"},{"1":"Kansas","2":"2012","3":"13.247210","4":"9341.957"},{"1":"Kentucky","2":"2007","3":"17.976406","4":"7759.095"},{"1":"Kentucky","2":"2008","3":"17.377035","4":"8069.342"},{"1":"Kentucky","2":"2009","3":"16.703621","4":"8416.562"},{"1":"Kentucky","2":"2010","3":"15.831109","4":"8586.506"},{"1":"Kentucky","2":"2011","3":"15.001671","4":"8724.397"},{"1":"Kentucky","2":"2012","3":"15.757031","4":"9076.766"},{"1":"Louisiana","2":"2007","3":"21.707510","4":"8769.674"},{"1":"Louisiana","2":"2008","3":"20.225765","4":"9095.864"},{"1":"Louisiana","2":"2009","3":"18.300158","4":"8888.986"},{"1":"Louisiana","2":"2010","3":"15.625450","4":"9573.448"},{"1":"Louisiana","2":"2011","3":"14.512162","4":"11832.118"},{"1":"Louisiana","2":"2012","3":"15.398054","4":"10643.446"},{"1":"Maine","2":"2007","3":"12.171599","4":"7143.904"},{"1":"Maine","2":"2008","3":"10.646336","4":"7687.306"},{"1":"Maine","2":"2009","3":"10.972327","4":"8078.580"},{"1":"Maine","2":"2010","3":"11.065762","4":"8461.556"},{"1":"Maine","2":"2011","3":"9.545046","4":"8854.168"},{"1":"Maine","2":"2012","3":"11.550250","4":"9058.135"},{"1":"Maryland","2":"2007","3":"10.866679","4":"8942.137"},{"1":"Maryland","2":"2008","3":"10.740963","4":"9290.689"},{"1":"Maryland","2":"2009","3":"9.892754","4":"9339.452"},{"1":"Maryland","2":"2010","3":"8.783883","4":"9630.120"},{"1":"Maryland","2":"2011","3":"8.626745","4":"10335.795"},{"1":"Maryland","2":"2012","3":"8.941916","4":"10393.295"},{"1":"Massachusetts","2":"2007","3":"7.572043","4":"8480.942"},{"1":"Massachusetts","2":"2008","3":"6.659939","4":"8847.383"},{"1":"Massachusetts","2":"2009","3":"6.093556","4":"9359.094"},{"1":"Massachusetts","2":"2010","3":"5.776095","4":"9646.240"},{"1":"Massachusetts","2":"2011","3":"6.150565","4":"9900.516"},{"1":"Massachusetts","2":"2012","3":"6.238859","4":"10085.547"},{"1":"Michigan","2":"2007","3":"10.400138","4":"7553.748"},{"1":"Michigan","2":"2008","3":"9.624355","4":"8024.254"},{"1":"Michigan","2":"2009","3":"9.000816","4":"8602.041"},{"1":"Michigan","2":"2010","3":"9.654868","4":"8965.320"},{"1":"Michigan","2":"2011","3":"9.382163","4":"9354.825"},{"1":"Michigan","2":"2012","3":"9.920888","4":"9711.272"},{"1":"Minnesota","2":"2007","3":"8.806108","4":"7788.179"},{"1":"Minnesota","2":"2008","3":"7.862747","4":"8323.128"},{"1":"Minnesota","2":"2009","3":"7.401740","4":"8429.205"},{"1":"Minnesota","2":"2010","3":"7.257423","4":"8868.903"},{"1":"Minnesota","2":"2011","3":"6.492050","4":"9231.297"},{"1":"Minnesota","2":"2012","3":"6.931245","4":"9581.459"},{"1":"Mississippi","2":"2007","3":"20.398273","4":"7523.679"},{"1":"Mississippi","2":"2008","3":"17.913111","4":"7867.644"},{"1":"Mississippi","2":"2009","3":"17.315161","4":"7943.778"},{"1":"Mississippi","2":"2010","3":"16.088942","4":"8222.972"},{"1":"Mississippi","2":"2011","3":"16.215916","4":"8917.204"},{"1":"Mississippi","2":"2012","3":"15.051544","4":"8898.043"},{"1":"Missouri","2":"2007","3":"14.345418","4":"7951.123"},{"1":"Missouri","2":"2008","3":"14.061195","4":"8356.444"},{"1":"Missouri","2":"2009","3":"12.724085","4":"8566.065"},{"1":"Missouri","2":"2010","3":"11.557350","4":"8864.693"},{"1":"Missouri","2":"2011","3":"11.397134","4":"9364.984"},{"1":"Missouri","2":"2012","3":"12.057746","4":"9412.174"},{"1":"Montana","2":"2007","3":"24.498098","4":"7245.310"},{"1":"Montana","2":"2008","3":"21.180170","4":"7731.746"},{"1":"Montana","2":"2009","3":"20.070839","4":"8225.733"},{"1":"Montana","2":"2010","3":"16.890373","4":"8550.507"},{"1":"Montana","2":"2011","3":"17.925146","4":"8635.553"},{"1":"Montana","2":"2012","3":"17.248453","4":"8834.581"},{"1":"Nebraska","2":"2007","3":"13.169402","4":"7815.974"},{"1":"Nebraska","2":"2008","3":"10.850286","4":"8388.321"},{"1":"Nebraska","2":"2009","3":"11.519190","4":"8432.506"},{"1":"Nebraska","2":"2010","3":"9.774693","4":"8339.078"},{"1":"Nebraska","2":"2011","3":"9.479756","4":"8938.258"},{"1":"Nebraska","2":"2012","3":"10.997818","4":"9027.095"},{"1":"Nevada","2":"2007","3":"16.842772","4":"8447.085"},{"1":"Nevada","2":"2008","3":"15.591915","4":"8722.517"},{"1":"Nevada","2":"2009","3":"11.880317","4":"9053.814"},{"1":"Nevada","2":"2010","3":"11.575836","4":"9083.331"},{"1":"Nevada","2":"2011","3":"10.169779","4":"9396.612"},{"1":"Nevada","2":"2012","3":"10.683987","4":"9463.811"},{"1":"New Hampshire","2":"2007","3":"9.584664","4":"7766.973"},{"1":"New Hampshire","2":"2008","3":"10.659510","4":"8207.878"},{"1":"New Hampshire","2":"2009","3":"8.477560","4":"8493.290"},{"1":"New Hampshire","2":"2010","3":"9.797003","4":"8887.403"},{"1":"New Hampshire","2":"2011","3":"7.075733","4":"9133.709"},{"1":"New Hampshire","2":"2012","3":"8.376215","4":"9275.258"},{"1":"New Jersey","2":"2007","3":"9.507301","4":"8811.962"},{"1":"New Jersey","2":"2008","3":"8.013147","4":"9222.979"},{"1":"New Jersey","2":"2009","3":"7.983130","4":"9368.678"},{"1":"New Jersey","2":"2010","3":"7.613554","4":"9782.875"},{"1":"New Jersey","2":"2011","3":"8.578022","4":"10107.520"},{"1":"New Jersey","2":"2012","3":"7.935292","4":"10169.675"},{"1":"New Mexico","2":"2007","3":"15.381750","4":"7558.702"},{"1":"New Mexico","2":"2008","3":"13.927470","4":"7740.546"},{"1":"New Mexico","2":"2009","3":"13.877677","4":"8080.925"},{"1":"New Mexico","2":"2010","3":"13.690132","4":"8202.298"},{"1":"New Mexico","2":"2011","3":"13.762094","4":"8116.322"},{"1":"New Mexico","2":"2012","3":"14.279203","4":"8328.786"},{"1":"New York","2":"2007","3":"9.748642","4":"8495.818"},{"1":"New York","2":"2008","3":"9.180743","4":"8569.393"},{"1":"New York","2":"2009","3":"8.659760","4":"9662.536"},{"1":"New York","2":"2010","3":"9.142714","4":"10064.969"},{"1":"New York","2":"2011","3":"9.152429","4":"10378.523"},{"1":"New York","2":"2012","3":"9.109303","4":"10584.938"},{"1":"North Carolina","2":"2007","3":"16.168266","4":"8063.099"},{"1":"North Carolina","2":"2008","3":"14.088799","4":"8700.542"},{"1":"North Carolina","2":"2009","3":"12.808267","4":"8643.108"},{"1":"North Carolina","2":"2010","3":"12.882751","4":"8941.341"},{"1":"North Carolina","2":"2011","3":"11.823957","4":"9430.015"},{"1":"North Carolina","2":"2012","3":"12.310631","4":"9213.426"},{"1":"North Dakota","2":"2007","3":"14.150944","4":"8019.196"},{"1":"North Dakota","2":"2008","3":"13.299232","4":"9057.166"},{"1":"North Dakota","2":"2009","3":"17.169487","4":"9554.081"},{"1":"North Dakota","2":"2010","3":"12.708389","4":"9262.688"},{"1":"North Dakota","2":"2011","3":"16.209141","4":"9357.655"},{"1":"North Dakota","2":"2012","3":"16.862585","4":"9762.331"},{"1":"Ohio","2":"2007","3":"11.362096","4":"7935.001"},{"1":"Ohio","2":"2008","3":"10.987793","4":"8327.595"},{"1":"Ohio","2":"2009","3":"9.232191","4":"8714.641"},{"1":"Ohio","2":"2010","3":"9.657021","4":"9111.079"},{"1":"Ohio","2":"2011","3":"9.072243","4":"9633.648"},{"1":"Ohio","2":"2012","3":"9.963171","4":"10004.137"},{"1":"Oklahoma","2":"2007","3":"15.849660","4":"7527.681"},{"1":"Oklahoma","2":"2008","3":"15.443618","4":"7931.668"},{"1":"Oklahoma","2":"2009","3":"15.703134","4":"8345.425"},{"1":"Oklahoma","2":"2010","3":"13.990725","4":"8498.271"},{"1":"Oklahoma","2":"2011","3":"14.663876","4":"9051.808"},{"1":"Oklahoma","2":"2012","3":"14.789496","4":"10328.142"},{"1":"Oregon","2":"2007","3":"13.093525","4":"7799.960"},{"1":"Oregon","2":"2008","3":"12.429784","4":"8137.074"},{"1":"Oregon","2":"2009","3":"11.097374","4":"8456.063"},{"1":"Oregon","2":"2010","3":"9.385889","4":"8718.182"},{"1":"Oregon","2":"2011","3":"9.918079","4":"8840.715"},{"1":"Oregon","2":"2012","3":"10.128738","4":"9024.574"},{"1":"Pennsylvania","2":"2007","3":"13.716778","4":"7733.581"},{"1":"Pennsylvania","2":"2008","3":"13.611750","4":"8205.150"},{"1":"Pennsylvania","2":"2009","3":"12.169864","4":"8621.342"},{"1":"Pennsylvania","2":"2010","3":"13.196621","4":"8993.591"},{"1":"Pennsylvania","2":"2011","3":"12.963163","4":"9088.208"},{"1":"Pennsylvania","2":"2012","3":"13.247794","4":"9367.311"},{"1":"Rhode Island","2":"2007","3":"7.989810","4":"8016.396"},{"1":"Rhode Island","2":"2008","3":"7.939416","4":"8450.801"},{"1":"Rhode Island","2":"2009","3":"10.060606","4":"8478.849"},{"1":"Rhode Island","2":"2010","3":"7.970802","4":"8740.536"},{"1":"Rhode Island","2":"2011","3":"8.352921","4":"9102.998"},{"1":"Rhode Island","2":"2012","3":"8.197905","4":"9825.839"},{"1":"South Carolina","2":"2007","3":"20.857384","4":"7940.633"},{"1":"South Carolina","2":"2008","3":"18.549509","4":"7417.742"},{"1":"South Carolina","2":"2009","3":"18.196621","4":"8541.533"},{"1":"South Carolina","2":"2010","3":"16.488773","4":"8507.438"},{"1":"South Carolina","2":"2011","3":"16.991524","4":"8082.526"},{"1":"South Carolina","2":"2012","3":"17.599247","4":"9155.914"},{"1":"South Dakota","2":"2007","3":"16.213215","4":"7485.425"},{"1":"South Dakota","2":"2008","3":"13.242822","4":"7846.365"},{"1":"South Dakota","2":"2009","3":"14.822422","4":"8382.745"},{"1":"South Dakota","2":"2010","3":"15.790696","4":"8941.512"},{"1":"South Dakota","2":"2011","3":"12.330527","4":"8785.533"},{"1":"South Dakota","2":"2012","3":"14.593781","4":"8999.776"},{"1":"Tennessee","2":"2007","3":"16.999395","4":"8520.772"},{"1":"Tennessee","2":"2008","3":"14.898732","4":"8878.680"},{"1":"Tennessee","2":"2009","3":"14.083103","4":"9392.887"},{"1":"Tennessee","2":"2010","3":"14.636814","4":"9758.742"},{"1":"Tennessee","2":"2011","3":"13.370816","4":"9955.722"},{"1":"Tennessee","2":"2012","3":"14.248202","4":"10042.992"},{"1":"Texas","2":"2007","3":"13.814322","4":"8231.546"},{"1":"Texas","2":"2008","3":"14.368134","4":"8635.682"},{"1":"Texas","2":"2009","3":"13.353091","4":"8816.372"},{"1":"Texas","2":"2010","3":"12.811095","4":"9158.674"},{"1":"Texas","2":"2011","3":"12.702162","4":"9250.748"},{"1":"Texas","2":"2012","3":"14.287167","4":"9422.007"},{"1":"Utah","2":"2007","3":"11.143411","4":"7450.866"},{"1":"Utah","2":"2008","3":"10.587511","4":"7655.977"},{"1":"Utah","2":"2009","3":"9.290283","4":"7778.574"},{"1":"Utah","2":"2010","3":"8.877112","4":"8144.333"},{"1":"Utah","2":"2011","3":"9.152750","4":"8263.460"},{"1":"Utah","2":"2012","3":"8.180087","4":"8436.980"},{"1":"Vermont","2":"2007","3":"8.578113","4":"6470.783"},{"1":"Vermont","2":"2008","3":"9.983588","4":"7001.787"},{"1":"Vermont","2":"2009","3":"9.678263","4":"7446.603"},{"1":"Vermont","2":"2010","3":"9.796406","4":"7750.811"},{"1":"Vermont","2":"2011","3":"7.701961","4":"8093.469"},{"1":"Vermont","2":"2012","3":"10.671238","4":"8274.615"},{"1":"Virginia","2":"2007","3":"12.512641","4":"8319.404"},{"1":"Virginia","2":"2008","3":"10.014828","4":"8824.716"},{"1":"Virginia","2":"2009","3":"9.354109","4":"9197.484"},{"1":"Virginia","2":"2010","3":"9.005652","4":"9492.535"},{"1":"Virginia","2":"2011","3":"9.435128","4":"9605.262"},{"1":"Virginia","2":"2012","3":"9.597490","4":"9650.780"},{"1":"Washington","2":"2007","3":"9.975588","4":"8181.282"},{"1":"Washington","2":"2008","3":"9.377587","4":"8587.277"},{"1":"Washington","2":"2009","3":"8.720776","4":"8727.235"},{"1":"Washington","2":"2010","3":"8.008331","4":"8955.260"},{"1":"Washington","2":"2011","3":"8.023939","4":"9150.754"},{"1":"Washington","2":"2012","3":"7.822134","4":"9314.179"},{"1":"West Virginia","2":"2007","3":"20.958958","4":"6473.385"},{"1":"West Virginia","2":"2008","3":"18.292095","4":"7137.078"},{"1":"West Virginia","2":"2009","3":"18.157707","4":"7698.746"},{"1":"West Virginia","2":"2010","3":"16.403658","4":"8095.007"},{"1":"West Virginia","2":"2011","3":"17.771332","4":"8893.134"},{"1":"West Virginia","2":"2012","3":"17.632570","4":"8612.638"},{"1":"Wisconsin","2":"2007","3":"12.707377","4":"6858.706"},{"1":"Wisconsin","2":"2008","3":"10.528697","4":"7578.225"},{"1":"Wisconsin","2":"2009","3":"9.646302","4":"8039.225"},{"1":"Wisconsin","2":"2010","3":"9.626346","4":"8317.235"},{"1":"Wisconsin","2":"2011","3":"9.939593","4":"8633.056"},{"1":"Wisconsin","2":"2012","3":"10.408328","4":"8796.105"},{"1":"Wyoming","2":"2007","3":"16.015375","4":"8434.864"},{"1":"Wyoming","2":"2008","3":"16.830740","4":"9086.335"},{"1":"Wyoming","2":"2009","3":"14.005016","4":"9498.962"},{"1":"Wyoming","2":"2010","3":"16.554895","4":"9332.430"},{"1":"Wyoming","2":"2011","3":"14.602637","4":"9363.593"},{"1":"Wyoming","2":"2012","3":"13.267186","4":"9455.043"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] .pull-right[ .content-box-green[ .green[**Example**]: Do cell phones cause more traffic fatalities? ] - No measure of cell phones *used* while driving - `cell_plans` as a **proxy** for cell phone usage - State-level data over 6 years ] --- # The Data I ```r glimpse(phones) ``` ``` ## Rows: 306 ## Columns: 8 ## $ year <fct> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2… ## $ state <fct> Alabama, Alaska, Arizona, Arkansas, California, Colorad… ## $ urban_percent <dbl> 30, 55, 45, 21, 54, 34, 84, 31, 100, 53, 39, 45, 11, 56… ## $ cell_plans <dbl> 8135.525, 6730.282, 7572.465, 8071.125, 8821.933, 8162.… ## $ cell_ban <fct> 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ text_ban <fct> 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ deaths <dbl> 18.075232, 16.301184, 16.930578, 19.595430, 12.104340, … ## $ year_num <dbl> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2… ``` --- # The Data II .pull-left[ .quitesmall[ ```r phones %>% count(state) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["n"],"name":[2],"type":["int"],"align":["right"]}],"data":[{"1":"Alabama","2":"6"},{"1":"Alaska","2":"6"},{"1":"Arizona","2":"6"},{"1":"Arkansas","2":"6"},{"1":"California","2":"6"},{"1":"Colorado","2":"6"},{"1":"Connecticut","2":"6"},{"1":"Delaware","2":"6"},{"1":"District of Columbia","2":"6"},{"1":"Florida","2":"6"},{"1":"Georgia","2":"6"},{"1":"Hawaii","2":"6"},{"1":"Idaho","2":"6"},{"1":"Illinois","2":"6"},{"1":"Indiana","2":"6"},{"1":"Iowa","2":"6"},{"1":"Kansas","2":"6"},{"1":"Kentucky","2":"6"},{"1":"Louisiana","2":"6"},{"1":"Maine","2":"6"},{"1":"Maryland","2":"6"},{"1":"Massachusetts","2":"6"},{"1":"Michigan","2":"6"},{"1":"Minnesota","2":"6"},{"1":"Mississippi","2":"6"},{"1":"Missouri","2":"6"},{"1":"Montana","2":"6"},{"1":"Nebraska","2":"6"},{"1":"Nevada","2":"6"},{"1":"New Hampshire","2":"6"},{"1":"New Jersey","2":"6"},{"1":"New Mexico","2":"6"},{"1":"New York","2":"6"},{"1":"North Carolina","2":"6"},{"1":"North Dakota","2":"6"},{"1":"Ohio","2":"6"},{"1":"Oklahoma","2":"6"},{"1":"Oregon","2":"6"},{"1":"Pennsylvania","2":"6"},{"1":"Rhode Island","2":"6"},{"1":"South Carolina","2":"6"},{"1":"South Dakota","2":"6"},{"1":"Tennessee","2":"6"},{"1":"Texas","2":"6"},{"1":"Utah","2":"6"},{"1":"Vermont","2":"6"},{"1":"Virginia","2":"6"},{"1":"Washington","2":"6"},{"1":"West Virginia","2":"6"},{"1":"Wisconsin","2":"6"},{"1":"Wyoming","2":"6"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] -- .pull-right[ .quitesmall[ ```r phones %>% count(year) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["year"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["n"],"name":[2],"type":["int"],"align":["right"]}],"data":[{"1":"2007","2":"51"},{"1":"2008","2":"51"},{"1":"2009","2":"51"},{"1":"2010","2":"51"},{"1":"2011","2":"51"},{"1":"2012","2":"51"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # The Data III .pull-left[ .quitesmall[ ```r phones %>% distinct(state) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]}],"data":[{"1":"Alabama"},{"1":"Alaska"},{"1":"Arizona"},{"1":"Arkansas"},{"1":"California"},{"1":"Colorado"},{"1":"Connecticut"},{"1":"Delaware"},{"1":"District of Columbia"},{"1":"Florida"},{"1":"Georgia"},{"1":"Hawaii"},{"1":"Idaho"},{"1":"Illinois"},{"1":"Indiana"},{"1":"Iowa"},{"1":"Kansas"},{"1":"Kentucky"},{"1":"Louisiana"},{"1":"Maine"},{"1":"Maryland"},{"1":"Massachusetts"},{"1":"Michigan"},{"1":"Minnesota"},{"1":"Mississippi"},{"1":"Missouri"},{"1":"Montana"},{"1":"Nebraska"},{"1":"Nevada"},{"1":"New Hampshire"},{"1":"New Jersey"},{"1":"New Mexico"},{"1":"New York"},{"1":"North Carolina"},{"1":"North Dakota"},{"1":"Ohio"},{"1":"Oklahoma"},{"1":"Oregon"},{"1":"Pennsylvania"},{"1":"Rhode Island"},{"1":"South Carolina"},{"1":"South Dakota"},{"1":"Tennessee"},{"1":"Texas"},{"1":"Utah"},{"1":"Vermont"},{"1":"Virginia"},{"1":"Washington"},{"1":"West Virginia"},{"1":"Wisconsin"},{"1":"Wyoming"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] -- .pull-right[ .quitesmall[ ```r phones %>% distinct(year) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["year"],"name":[1],"type":["fctr"],"align":["left"]}],"data":[{"1":"2007"},{"1":"2008"},{"1":"2009"},{"1":"2010"},{"1":"2011"},{"1":"2012"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # The Data IV .quitesmall[ ```r phones %>% summarize(States = n_distinct(state), Years = n_distinct(year)) ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["States"],"name":[1],"type":["int"],"align":["right"]},{"label":["Years"],"name":[2],"type":["int"],"align":["right"]}],"data":[{"1":"51","2":"6"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] --- # The Data: With plm .pull-left[ ```r # install.packages("plm") library(plm) pdim(phones, index=c("state","year")) ``` ``` ## Balanced Panel: n = 51, T = 6, N = 306 ``` ] .pull-right[ - **`plm` package** for panel data in R - `pdim()` checks dimensions of panel dataset - `index=` vector of "group" & "year" variables - Returns with a summary of: - `n` groups - `T` periods - `N` total observaitons ] --- # Pooled Regression I - What if we just ran a standard regression: `$$\hat{Y_{it}}=\beta_0+\beta_1X_{it}+u_{it}$$` -- - `\(N\)` number of `\(i\)` groups (e.g. U.S. States) - `\(T\)` number of `\(t\)` periods (e.g. years) - This is a .hi[pooled regression model]: treats all observations as independent --- # Pooled Regression II .smallest[ ```r pooled <- lm(deaths ~ cell_plans, data = phones) pooled %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"(Intercept)","2":"17.3371034167","3":"0.975384504","4":"17.774635","5":"5.821724e-49"},{"1":"cell_plans","2":"-0.0005666385","3":"0.000106975","4":"-5.296926","5":"2.264086e-07"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] --- # Pooled Regression III .pull-left[ .code60[ ```r ggplot(data = phones)+ aes(x = cell_plans, y = deaths)+ geom_point()+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven")+ theme_bw(base_family = "Fira Sans Condensed", base_size=14) ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-18-1.png" width="504" /> ] --- # Pooled Regression III .pull-left[ .code60[ ```r ggplot(data = phones)+ aes(x = cell_plans, y = deaths)+ geom_point()+ * geom_smooth(method = "lm", color = "red")+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven")+ theme_bw(base_family = "Fira Sans Condensed", base_size=14) ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-19-1.png" width="504" /> ] --- # Recap: Assumptions about Errors .pull-left[ .smallest[ - Recall the .hi[4 critical **assumptions** about `\\(u\\)`]: 1. The expected value of the residuals is 0 `$$E[u]=0$$` 2. The variance of the residuals over `\(X\)` is constant: `$$var(u|X)=\sigma^2_{u}$$` 3. Errors are not correlated across observations: `$$cor(u_i,u_j)=0 \quad \forall i \neq j$$` 4. There is no correlation between `\(X\)` and the error term: `$$cor(X, u)=0 \text{ or } E[u|X]=0$$` ] ] .pull-right[ .center[  ] ] --- # Biases of Pooled Regression `$$\hat{Y_{it}}=\beta_0+\beta_1X_{it}+\epsilon_{it}$$` - .hi-purple[Assumption 3]: `\(cor(u_i,u_j)=0 \quad \forall \, i \neq j\)` - Pooled regression model is **biased** because it ignores: - Multiple observations from same group `\(i\)` - Multiple observations from same time `\(t\)` - Thus, errors are .hi[serially] or .hi[auto-correlated]; `\(cor(u_i, u_j) \neq 0\)` within same `\(i\)` and within same `\(t\)` --- # Biases of Pooled Regression: Our Example `$$\widehat{\text{Deaths}_{it}}=\beta_0+\beta_1 \, \text{Cell Phones}_{it}+u_{it}$$` - Multiple observations from same state `\(i\)` - Probably similarities among `\(u\)` for obs in same state - Residuals on observations from same state are likely correlated - Multiple observations from same year `\(t\)` - Probably similarities among `\(u\)` for obs in same year - Residuals on observations from same year are likely correlated --- # Example: Consider Just 5 States .pull-left[ .code60[ ```r phones %>% filter(state %in% c("District of Columbia", "Maryland", "Texas", "California", "Kansas")) %>% ggplot(data = .)+ aes(x = cell_plans, y = deaths, * color = state)+ * geom_point()+ * geom_smooth(method = "lm")+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven", color = NULL)+ theme_bw(base_family = "Fira Sans Condensed", base_size=14)+ theme(legend.position = "top") ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-20-1.png" width="504" /> ] --- # Example: Consider Just 5 States .pull-left[ .code60[ ```r phones %>% filter(state %in% c("District of Columbia", "Maryland", "Texas", "California", "Kansas")) %>% ggplot(data = .)+ aes(x = cell_plans, y = deaths, color = state)+ geom_point()+ geom_smooth(method = "lm")+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven", color = NULL)+ theme_bw(base_family = "Fira Sans Condensed", base_size=14)+ * theme(legend.position = "none")+ * facet_wrap(~state, ncol=3) ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-21-1.png" width="504" /> ] --- # Look at All States .pull-left[ .code60[ ```r *ggplot(data = phones)+ aes(x = cell_plans, y = deaths, color = state)+ geom_point()+ geom_smooth(method = "lm")+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven", color = NULL)+ theme_bw(base_family = "Fira Sans Condensed")+ theme(legend.position = "none")+ * facet_wrap(~state, ncol=7) ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-22-1.png" width="504" /> ] --- # The Bias in our Pooled Regression .smallest[ `$$\widehat{\text{Deaths}_{it}}=\beta_0+\beta_1 \, \text{Cell Phones}_{it}+\text{u}_{it}$$` - `\(\text{Cell Phones}_{it}\)` is .hi-purple[endogenous]: ] -- .smallest[ `$$cor(\text{u}_{it}, \text{cell phones}_{it}) \neq 0 \quad \quad E[\text{u}_{it}|\text{cell phones}_{it}] \neq 0$$` ] -- .smallest[ - Things in `\(u_{it}\)` correlated with `\(\text{Cell phones}_{it}\)`: - infrastructure spending, population, urban vs. rural, more/less cautious citizens, cultural attitudes towards driving, texting, etc ] -- .smallest[ - A lot of these things vary systematically **by State**! - `\(cor(\text{u}_{it_1}, \text{u}_{it_2})\neq 0\)` - Error in State `\(i\)` during `\(t_1\)` correlates with error in State `\(i\)` during `\(t_2\)` - things in State that don’t change over time ] --- class: inverse, center, middle # Fixed Effects Model --- # Fixed Effects: DAG .pull-left[ .smallest[ - A simple pooled model likely contains lots of omitted variable bias - Many (often unobservable) factors that determine both Phones & Deaths - Culture, infrastructure, population, geography, institutions, etc ] ] .pull-right[ 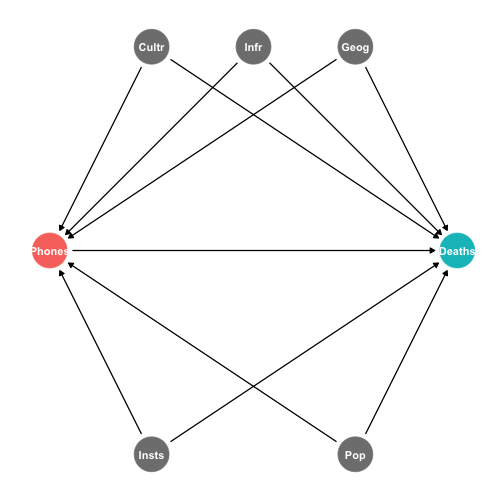<!-- --> ] --- # Fixed Effects: DAG .pull-left[ .smallest[ - A simple pooled model likely contains lots of omitted variable bias - Many (often unobservable) factors that determine both Phones & Deaths - Culture, infrastructure, population, geography, institutions, etc - But the beauty of this is that .hi-turquoise[most of these factors systematically vary by U.S. State and are stable over time!] - We can simply .hi-purple[“control for State”] to safely remove the influence of all of these factors! ] ] .pull-right[ 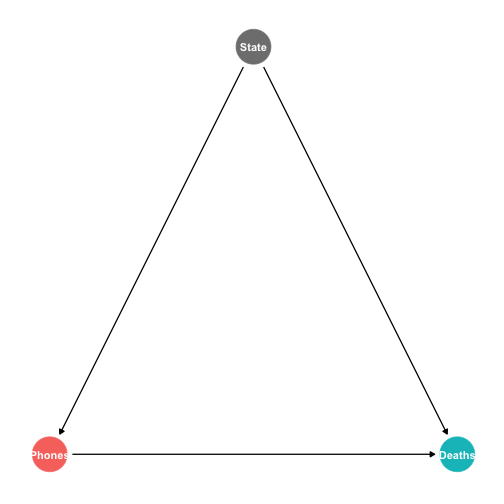<!-- --> ] --- # Fixed Effects: Decomposing `\(\text{u}_{it}\)` - Much of the endogeneity in `\(X_{it}\)` can be explained by systematic differences across `\(i\)` (groups) -- - Exploit the systematic variation across groups with a .hi[fixed effects model] -- - *Decompose* the model error term into two parts: `$$\text{u}_{it} = \alpha_i + \epsilon_{it}$$` --- # Fixed Effects: `\(\alpha_i\)` - *Decompose* the model error term into two parts: `$$\text{u}_{it} = \color{#6A5ACD}{\alpha_i} + \epsilon_{it}$$` - `\(\color{#6A5ACD}{\alpha_i}\)` are .hi-purple[group-specific fixed effects] - group `\(i\)` tends to have higher or lower `\(\hat{Y}\)` than other groups given regressor(s) `\(X_{it}\)` - estimate a separate `\(\alpha_i\)` for each group `\(i\)` - essentially, estimate a separate constant (intercept) _for each group_ - notice this is stable over time within each group (subscript only `\(i\)`, no `\(t)\)` - .hi-purple[This includes **all** factors that do not change _within_ group *i* over time] --- # Fixed Effects: `\(\epsilon_{it}\)` `$$\text{u}_{it} = \color{#6A5ACD}{\alpha_i} + \color{#D7250E}{\epsilon_{it}}$$` - `\(\color{#D7250E}{\epsilon_{it}}\)` is the remaining random error - As usual in OLS, assume the 4 typical assumptions about this error: - `\(E[\epsilon_{it}]=0\)`, `\(var[\epsilon_{it}]=\sigma^2_{\epsilon}\)`, `\(cor(\epsilon_{it}, \epsilon_{jt})=0\)`, `\(cor(\epsilon_{it}, X_{it})=0\)` - `\(\color{#D7250E}{\epsilon_{it}}\)` includes all other factors affecting `\(Y_{it}\)` *not* contained in group effect `\(\alpha_i\)` - i.e. differences *within* each group that *change* over time - Be careful: `\(X_{it}\)` can still be endogenous from other factors! --- # Fixed Effects: New Regression Equation `$$\widehat{Y}_{it} = \beta_0+\beta_1 X_{it} +\color{#6A5ACD}{\alpha_i} + \color{#D7250E}{\epsilon_{it}}$$` - We've pulled `\(\color{#6A5ACD}{\alpha_i}\)` out of the original error term into the regression - Essentially we’ll estimate an intercept for each .purple[group] (minus one, which is `\(\beta_0)\)` - avoiding the dummy variable trap - Must have multiple observations (over time) for each group (i.e. panel data) --- # Fixed Effects: Our Example `$$\widehat{\text{Deaths}}_{it} = \beta_0+\beta_1 \text{Cell phones}_{it} +\color{#6A5ACD}{\alpha_i}+ \color{#D7250E}{\epsilon_{it}}$$` - `\(\color{#6A5ACD}{\alpha_i}\)` is the .hi-purple[State fixed effect] - Captures everything unique about each state `\(i\)` that *does not change over time* - culture, institutions, history, geography, climate, etc! - There could *still* be factors in `\(\color{#D7250E}{\epsilon_{it}}\)` that are correlated with `\(\text{Cell phones}_{it}\)`! - things that do change over time within States - perhaps individual States have cell phone bans for *some* years in our data --- # Estimating Fixed Effects Models `$$\widehat{Y}_{it} = \beta_0+\beta_1 X_{it} +\alpha_i+\epsilon_{it}$$` - Two methods to estimate fixed effects models: 1. Least Squares Dummy Variable (LSDV) approach 2. De-meaned data approach --- class: inverse, center, middle # Least Squares Dummy Variable Approach --- # Least Squares Dummy Variable Approach .smallest[ `$$\widehat{Y_{it}}=\beta_0+\beta_1X_{it}+\beta_2 D_{1i}+ \beta_3 D_{2i} + \cdots +\beta_N D_{(N-1)i}+\epsilon_{it}$$` - A dummy variable `\(D_{i} = \{0,1\}\)` for each possible group - `\(=1\)` if observation `\(it\)` is from group `\(i\)`, otherwise `\(=0\)` ] -- .smallest[ - If there are `\(N\)` groups: - Include `\(N-1\)` dummies (to avoid **dummy variable trap**) and `\(\beta_0\)` is the reference category<sup>.magenta[†]</sup> - So we are estimating a different intercept for each group ] -- .smallest[ - Sounds like a lot of work, automatic in `R` ] -- .footnote[<sup>.magenta[†]</sup> If we do not estimate `\\(\beta_0\\)`, we could include all N dummies. In either case, `\\(\beta_0\\)` takes the place of one category-dummy.] --- # Least Squares Dummy Variable Approach: Our Example .content-box-green[ .green[**Example**]: `$$\widehat{\text{Deaths}_{it}}=\beta_0+\beta_1\text{Cell Phones}_{it}+\text{Alaska}_i+ \cdots +\text{Wyoming}_i$$` ] - Let Alabama be the reference category `\((\beta_0)\)`, include all other States --- # Our Example in R I `$$\widehat{\text{Deaths}_{it}}=\beta_0+\beta_1\text{Cell Phones}_{it}+\text{Alaska}_i+ \cdots +\text{Wyoming}_i$$` - If `state` is a `factor` variable, just include it in the regression - `R` automatically creates `\(N-1\)` dummy variables and includes them in the regression - Keeps intercept and leaves out first group dummy --- # Our Example in R II .tiny[ ```r fe_reg_1 <- lm(deaths ~ cell_plans + state, data = phones) fe_reg_1 %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"(Intercept)","2":"25.507679925","3":"1.0176400289","4":"25.06552337","5":"1.241581e-70"},{"1":"cell_plans","2":"-0.001203742","3":"0.0001013125","4":"-11.88147584","5":"3.483442e-26"},{"1":"stateAlaska","2":"-2.484164783","3":"0.6745076282","4":"-3.68293060","5":"2.816972e-04"},{"1":"stateArizona","2":"-1.510577383","3":"0.6704569688","4":"-2.25305643","5":"2.510925e-02"},{"1":"stateArkansas","2":"3.192662931","3":"0.6664383936","4":"4.79063476","5":"2.829319e-06"},{"1":"stateCalifornia","2":"-4.978668651","3":"0.6655467951","4":"-7.48056889","5":"1.206933e-12"},{"1":"stateColorado","2":"-4.344553493","3":"0.6654735335","4":"-6.52851432","5":"3.588784e-10"},{"1":"stateConnecticut","2":"-6.595185530","3":"0.6654428902","4":"-9.91097152","5":"8.698802e-20"},{"1":"stateDelaware","2":"-2.098393628","3":"0.6666483193","4":"-3.14767707","5":"1.842218e-03"},{"1":"stateDistrict of Columbia","2":"6.355790010","3":"1.2897172620","4":"4.92804911","5":"1.499627e-06"},{"1":"stateFlorida","2":"-1.034765583","3":"0.6656584131","4":"-1.55449937","5":"1.213104e-01"},{"1":"stateGeorgia","2":"-2.169399521","3":"0.6661315964","4":"-3.25671314","5":"1.280549e-03"},{"1":"stateHawaii","2":"-2.991513070","3":"0.6662205495","4":"-4.49027439","5":"1.080031e-05"},{"1":"stateIdaho","2":"-2.460813292","3":"0.6721520915","4":"-3.66109594","5":"3.055013e-04"},{"1":"stateIllinois","2":"-5.062067730","3":"0.6657585536","4":"-7.60345880","5":"5.588057e-13"},{"1":"stateIndiana","2":"-5.228465877","3":"0.6696565924","4":"-7.80768223","5":"1.528835e-13"},{"1":"stateIowa","2":"-3.249588932","3":"0.6705449588","4":"-4.84619098","5":"2.192457e-06"},{"1":"stateKansas","2":"-1.458162923","3":"0.6654570677","4":"-2.19122013","5":"2.934450e-02"},{"1":"stateKentucky","2":"1.091575116","3":"0.6671138362","4":"1.63626514","5":"1.030226e-01"},{"1":"stateLouisiana","2":"3.917881911","3":"0.6715684978","4":"5.83392748","5":"1.642070e-08"},{"1":"stateMaine","2":"-4.628329229","3":"0.6691172795","4":"-6.91706726","5":"3.729478e-11"},{"1":"stateMaryland","2":"-4.243098130","3":"0.6697410295","4":"-6.33543107","5":"1.070029e-09"},{"1":"stateMassachusetts","2":"-7.793437109","3":"0.6672061350","4":"-11.68070361","5":"1.625361e-25"},{"1":"stateMichigan","2":"-5.368956146","3":"0.6657520297","4":"-8.06449835","5":"2.912490e-14"},{"1":"stateMinnesota","2":"-7.572126702","3":"0.6657464272","4":"-11.37389011","5":"1.685655e-24"},{"1":"stateMississippi","2":"1.561598654","3":"0.6689602297","4":"2.33436696","5":"2.035658e-02"},{"1":"stateMissouri","2":"-2.281345191","3":"0.6656120805","4":"-3.42743958","5":"7.106112e-04"},{"1":"stateMontana","2":"4.003216157","3":"0.6692246488","4":"5.98187195","5":"7.458452e-09"},{"1":"stateNebraska","2":"-4.322474652","3":"0.6667641052","4":"-6.48276447","5":"4.658371e-10"},{"1":"stateNevada","2":"-1.849698565","3":"0.6655435257","4":"-2.77923005","5":"5.856038e-03"},{"1":"stateNew Hampshire","2":"-6.127382094","3":"0.6660295641","4":"-9.19986503","5":"1.357559e-17"},{"1":"stateNew Jersey","2":"-5.707365784","3":"0.6688922440","4":"-8.53256386","5":"1.314338e-15"},{"1":"stateNew Mexico","2":"-1.719158568","3":"0.6716721629","4":"-2.55952035","5":"1.106160e-02"},{"1":"stateNew York","2":"-4.754827932","3":"0.6694121494","4":"-7.10299019","5":"1.225067e-11"},{"1":"stateNorth Carolina","2":"-1.529215200","3":"0.6654724423","4":"-2.29793918","5":"2.237838e-02"},{"1":"stateNorth Dakota","2":"0.595880660","3":"0.6659608543","4":"0.89476830","5":"3.717581e-01"},{"1":"stateOhio","2":"-4.683202635","3":"0.6654474519","4":"-7.03767461","5":"1.815281e-11"},{"1":"stateOklahoma","2":"-0.065432340","3":"0.6660893891","4":"-0.09823357","5":"9.218243e-01"},{"1":"stateOregon","2":"-4.271677763","3":"0.6667266398","4":"-6.40694028","5":"7.158251e-10"},{"1":"statePennsylvania","2":"-1.922414465","3":"0.6658670533","4":"-2.88708453","5":"4.223056e-03"},{"1":"stateRhode Island","2":"-6.533207516","3":"0.6655747188","4":"-9.81588893","5":"1.725455e-19"},{"1":"stateSouth Carolina","2":"2.566280693","3":"0.6685038446","4":"3.83884209","5":"1.561121e-04"},{"1":"stateSouth Dakota","2":"-0.889041844","3":"0.6673510107","4":"-1.33219525","5":"1.839901e-01"},{"1":"stateTennessee","2":"0.543722021","3":"0.6675006813","4":"0.81456399","5":"4.160850e-01"},{"1":"stateTexas","2":"-1.215305938","3":"0.6654309611","4":"-1.82634414","5":"6.897223e-02"},{"1":"stateUtah","2":"-6.393350380","3":"0.6723735941","4":"-9.50862800","5":"1.547018e-18"},{"1":"stateVermont","2":"-7.070384958","3":"0.6803787706","4":"-10.39183652","5":"2.613517e-21"},{"1":"stateVirginia","2":"-4.468646712","3":"0.6660140850","4":"-6.70953785","5":"1.263262e-10"},{"1":"stateWashington","2":"-6.236757171","3":"0.6654881222","4":"-9.37170321","5":"4.069919e-18"},{"1":"stateWest Virginia","2":"2.106291665","3":"0.6744981466","4":"3.12275382","5":"1.999170e-03"},{"1":"stateWisconsin","2":"-5.356989528","3":"0.6712322806","4":"-7.98082822","5":"5.015723e-14"},{"1":"stateWyoming","2":"0.773613122","3":"0.6660728030","4":"1.16145430","5":"2.465475e-01"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] --- class: inverse, center, middle # De-meaned Approach --- # De-meaned Approach I - Alternatively, we can control our regression for group fixed effects without directly estimating them - We simply .hi-purple[de-mean the data for each group] -- - For each group `\(i\)`, find the means (over time, `\(t)\)`: `$$\bar{Y}_i=\beta_0+\beta_1 \bar{X}_i+\bar{\alpha}_i+\bar{\epsilon}_{it}$$` -- - Where: - `\(\bar{Y}_i\)`: average value of `\(Y_{it}\)` for group `\(i\)` - `\(\bar{X}_i\)`: average value of `\(X_{it}\)` for group `\(i\)` - `\(\bar{\alpha}_i\)`: average value of `\(\alpha_{i}\)` for group `\(i\)` `\((=\alpha_i)\)` - `\(\bar{\epsilon}_{it}=0\)`, by assumption 1 --- # De-meaned Approach II .smallest[ `$$\begin{align*} \widehat{Y_{it}}&=\beta_0+\beta_1X_{it}+u_{it}\\ \bar{Y}_i&=\beta_0+\beta_1 \bar{X}_i+\bar{\alpha}_i+\bar{\epsilon}_i\\ \end{align*}$$` ] -- .smallest[ - Subtract the means equation from the pooled equation to get: `$$\begin{align*} Y_i-\bar{Y}_i&=\beta_1(X_{it}-\bar{X}_i)+\tilde{\epsilon}_{it}\\ \tilde{Y}_{it}&=\beta_1 \tilde{X}_{it}+\tilde{\epsilon}_{it}\\ \end{align*}$$` ] -- .smallest[ - Within each group `\(i\)`, the de-meaned variables `\(\tilde{Y}_{it}\)` and `\(\tilde{X}_{it}\)`'s all have a mean of 0<sup>.magenta[†]</sup> - Variables that don't change over time will drop out of analysis altogether - Removes any source of variation **across** groups to only work with variation **within** each group ] .footnote[<sup>.magenta[†]</sup> Recall **Rule 4** from the [2.3 class notes](class/2.1-class/#the-summation-operator) on the Summation Operator: `\\(\sum(X_i-\bar{X})=0\\)`] --- # De-meaned Approach III `$$\tilde{Y}_{it}=\beta_1 \tilde{X}_{it}+\tilde{\epsilon}_{it}$$` - Yields identical results to dummy variable approach - More useful when we have many groups (would be many dummies) - Demonstrates **intuition** behind fixed effects: - Converts all data to deviations from the mean of each group - All groups are “centered” at 0 - Fixed effects are often called the .hi-purple[“within” estimators], they exploit variation *within* groups, not *across* groups --- # De-meaned Approach IV - We are basically comparing groups *to themselves* over time - apples to apples comparison - e.g. Maryland in 2000 vs. Maryland in 2005 - Ignore all differences *between* groups, only look at differences *within* groups over time --- # De-Meaning the Data in R I .pull-left[ ```r # get means of Y and X by state means_state<-phones %>% group_by(state) %>% summarize(avg_deaths = mean(deaths), avg_phones = mean(cell_plans)) # look at it means_state ``` ] -- .pull-right[ .tiny[ <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["state"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["avg_deaths"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["avg_phones"],"name":[3],"type":["dbl"],"align":["right"]}],"data":[{"1":"Alabama","2":"14.786711","3":"8906.370"},{"1":"Alaska","2":"13.612953","3":"7817.759"},{"1":"Arizona","2":"14.249825","3":"8097.482"},{"1":"Arkansas","2":"17.543881","3":"9268.153"},{"1":"California","2":"9.659712","3":"9029.594"},{"1":"Colorado","2":"10.351405","3":"8981.762"},{"1":"Connecticut","2":"8.141739","3":"8947.729"},{"1":"Delaware","2":"12.209610","3":"9304.052"},{"1":"District of Columbia","2":"8.015895","3":"19811.205"},{"1":"Florida","2":"13.544635","3":"9078.592"},{"1":"Georgia","2":"12.254076","3":"9208.125"},{"1":"Hawaii","2":"11.409619","3":"9226.687"},{"1":"Idaho","2":"13.452557","3":"7970.406"},{"1":"Illinois","2":"9.476048","3":"9112.889"},{"1":"Indiana","2":"10.450802","3":"8164.885"},{"1":"Iowa","2":"12.519330","3":"8090.407"},{"1":"Kansas","2":"13.400258","3":"8846.797"},{"1":"Kentucky","2":"16.441146","3":"8438.778"},{"1":"Louisiana","2":"17.628183","3":"9800.590"},{"1":"Maine","2":"10.991887","3":"8213.941"},{"1":"Maryland","2":"9.642157","3":"9655.248"},{"1":"Massachusetts","2":"6.415176","3":"9386.620"},{"1":"Michigan","2":"9.663871","3":"8701.910"},{"1":"Minnesota","2":"7.458552","3":"8703.695"},{"1":"Mississippi","2":"17.163824","3":"8228.887"},{"1":"Missouri","2":"12.690488","3":"8752.581"},{"1":"Montana","2":"19.635513","3":"8203.905"},{"1":"Nebraska","2":"10.965191","3":"8490.205"},{"1":"Nevada","2":"12.790768","3":"9027.862"},{"1":"New Hampshire","2":"8.995114","3":"8627.418"},{"1":"New Jersey","2":"8.271741","3":"9577.281"},{"1":"New Mexico","2":"14.153055","3":"8004.596"},{"1":"New York","2":"9.165598","3":"9626.030"},{"1":"North Carolina","2":"13.347112","3":"8831.922"},{"1":"North Dakota","2":"15.066630","3":"9168.853"},{"1":"Ohio","2":"10.045752","3":"8954.350"},{"1":"Oklahoma","2":"15.073418","3":"8613.832"},{"1":"Oregon","2":"11.008898","3":"8496.095"},{"1":"Pennsylvania","2":"13.150995","3":"8668.197"},{"1":"Rhode Island","2":"8.418577","3":"8769.236"},{"1":"South Carolina","2":"18.113843","3":"8274.298"},{"1":"South Dakota","2":"14.498910","3":"8406.893"},{"1":"Tennessee","2":"14.706177","3":"9424.966"},{"1":"Texas","2":"13.555995","3":"8919.171"},{"1":"Utah","2":"9.538526","3":"7955.032"},{"1":"Vermont","2":"9.401595","3":"7506.345"},{"1":"Virginia","2":"9.986641","3":"9181.697"},{"1":"Washington","2":"8.654726","3":"8819.331"},{"1":"West Virginia","2":"18.202720","3":"7818.331"},{"1":"Wisconsin","2":"10.476107","3":"8037.092"},{"1":"Wyoming","2":"15.212642","3":"9195.204"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # De-Meaning the Data in R II .pull-left[ .code60[ ```r ggplot(data = means_state)+ aes(x = fct_reorder(state, avg_deaths), y = avg_deaths, color = state)+ geom_point()+ geom_segment(aes(y = 0, yend = avg_deaths, x = state, xend = state))+ coord_flip()+ labs(x = "Cell Phones Per 10,000 People", y = "Deaths Per Billion Miles Driven", color = NULL)+ theme_bw(base_family = "Fira Sans Condensed", base_size=10)+ theme(legend.position = "none") ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-26-1.png" width="504" /> ] --- # Visualizing "Within Estimates" for the 5 States <img src="4.1-slides_files/figure-html/unnamed-chunk-28-1.gif" style="display: block; margin: auto;" /> --- # Visualizing "Within Estimates" for All 51 States <img src="4.1-slides_files/figure-html/unnamed-chunk-30-1.gif" style="display: block; margin: auto;" /> --- # De-meaned Approach in R I - The `plm` package is designed for panel data - `plm()` function is just like `lm()`, with some additional arguments: - `index="group_variable_name"` set equal to the name of your `factor` variable for the groups - `model=` set equal to `"within"` to use fixed-effects (within-estimator) ```r #install.packages("plm") library(plm) fe_reg_1_alt<-plm(deaths ~ cell_plans, data = phones, index = "state", model = "within") ``` --- # De-meaned Approach in R II .quitesmall[ ```r fe_reg_1_alt %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"cell_plans","2":"-0.001203742","3":"0.0001013125","4":"-11.88148","5":"3.483442e-26"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] --- class: inverse, center, middle # Two-Way Fixed Effects --- # Two-Way Fixed Effects .pull-left[ .smallest[ - State fixed effect controls for all factors that vary by state but are stable over time - But there are still other (often unobservable) factors that affect both Phones and Deaths, that *don’t* vary by State - The country’s macroeconomic performance, federal laws, etc ] ] .pull-right[ 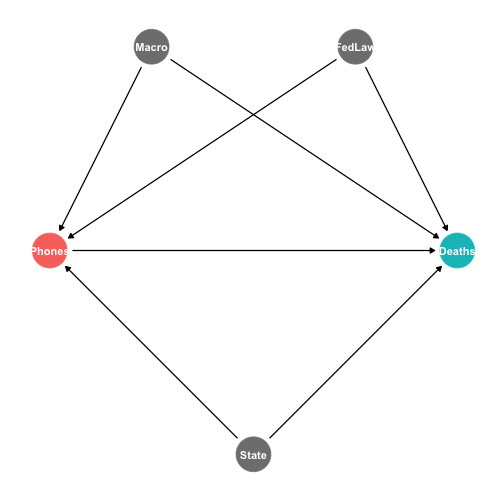<!-- --> ] --- # Two-Way Fixed Effects .pull-left[ .smallest[ - State fixed effect controls for all factors that vary by state but are stable over time - But there are still other (often unobservable) factors that affect both Phones and Deaths, that *don’t* vary by State - The country’s macroeconomic performance, federal laws, etc - If these factors systematically vary over time, but are the same by State, then we can .hi-purple[“control for Year”] to safely remove the influence of all of these factors! ] ] .pull-right[ 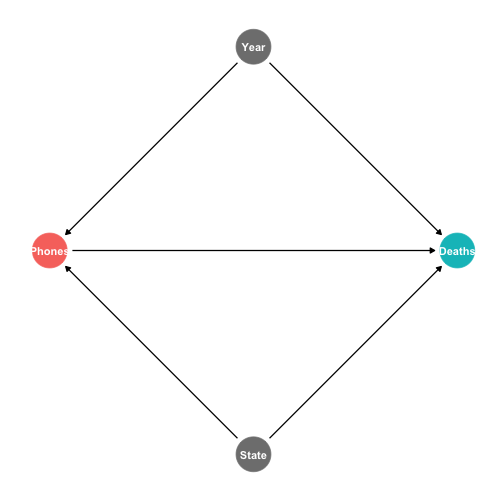<!-- --> ] --- # Two-Way Fixed Effects - A .hi[one-way fixed effects model] estimates a fixed effect for **groups** -- - .hi[Two-way fixed effects model] estimates fixed effects for *both* **groups** *and* **time periods** `$$\hat{Y_{it}}=\beta_0+\beta_1 X_{it}+ \color{#6A5ACD}{\alpha_{i}} + \color{#44C1C4}{\theta_{t}} + \color{#e64173}{\nu_{it}}$$` - `\(\color{#6A5ACD}{\alpha_{i}}\)`: group fixed effects - accounts for **time-invariant differences across groups** - `\(\color{#44C1C4}{\theta_{t}}\)`: time fixed effects - accounts for **group-invariant differences over time** - `\(\color{#e64173}{\nu_{it}}\)` remaining random error - all remaining factors that affect `\(Y_{it}\)` that vary by state *and* change over time --- # Two-Way Fixed Effects: Our Example `$$\widehat{\text{Deaths}}_{it} = \beta_0+\beta_1 \text{Cell phones}_{it} +\color{#6A5ACD}{\alpha_{i}} + \color{#44C1C4}{\theta_{t}} + \color{#e64173}{\nu_{it}}$$` - `\(\color{#6A5ACD}{\alpha_{i}}\)`: .purple[State fixed effects] - differences **across states** that are **stable over time** (note subscript `\(i\)` only) - e.g. geography, culture, (unchanging) state laws - `\(\color{#44C1C4}{\theta_{t}}\)`: .turquoise[Year fixed effects] - differences **over time** that are **stable across states** (note subscript `\(t\)` only) - e.g. economy-wide macroeconomic changes, *federal* laws passed --- # Visualizing Year Effects I .smallest[ ```r # find averages for years means_year<-phones %>% group_by(year) %>% summarize(avg_deaths = mean(deaths), avg_phones = mean(cell_plans)) means_year ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["year"],"name":[1],"type":["fctr"],"align":["left"]},{"label":["avg_deaths"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["avg_phones"],"name":[3],"type":["dbl"],"align":["right"]}],"data":[{"1":"2007","2":"14.00751","3":"8064.531"},{"1":"2008","2":"12.87156","3":"8482.903"},{"1":"2009","2":"12.08632","3":"8859.706"},{"1":"2010","2":"11.61487","3":"9134.592"},{"1":"2011","2":"11.36431","3":"9485.238"},{"1":"2012","2":"11.65666","3":"9660.474"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] --- # Visualizing Year Effects II .pull-left[ .code60[ ```r ggplot(data = phones)+ aes(x = year, y = deaths)+ geom_point(aes(color = year))+ # Add the yearly means as black points geom_point(data = means_year, aes(x = year, y = avg_deaths), size = 3, color = "black")+ geom_path(data = means_year, aes(x = year, y = avg_deaths), size = 1)+ theme_bw(base_family = "Fira Sans Condensed", base_size = 14)+ theme(legend.position = "none") ``` ] ] .pull-right[ <img src="4.1-slides_files/figure-html/unnamed-chunk-35-1.png" width="504" /> ] --- # Estimating Two-Way Fixed Effects `$$\widehat{Y}_{it} = \beta_0+\beta_1 X_{it} +\alpha_i+\theta_t+\nu_{it}$$` - As before, several equivalent ways to estimate two-way fixed effects models: 1) **Least Squares Dummy Variable (LSDV) Approach**: add dummies for both groups and time periods (separate intercepts for groups and times) -- 2) **Fully De-meaned data**: `$$\tilde{Y}_{it}=\beta_1\tilde{X}_{it}+\tilde{\nu}_{it}$$` where for each variable: `\(\tilde{var}_{it}=var_{it}-\overline{var}_{t}-\overline{var}_{i}\)` -- 3) **Hybrid**: de-mean for one effect (groups or years) and add dummies for the other effect (years or groups) --- # LSDV Method .quitesmall[ .code60[ ```r fe2_reg_1 <- lm(deaths ~ cell_plans + state + year, data = phones) fe2_reg_1 %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"(Intercept)","2":"18.9304707399","3":"1.4511323962","4":"13.0453092","5":"5.427406e-30"},{"1":"cell_plans","2":"-0.0002995294","3":"0.0001723149","4":"-1.7382677","5":"8.339982e-02"},{"1":"stateAlaska","2":"-1.4998292482","3":"0.6241082951","4":"-2.4031554","5":"1.698648e-02"},{"1":"stateArizona","2":"-0.7791714713","3":"0.6113519094","4":"-1.2745057","5":"2.036724e-01"},{"1":"stateArkansas","2":"2.8655344756","3":"0.5985062952","4":"4.7878101","5":"2.895040e-06"},{"1":"stateCalifornia","2":"-5.0900897113","3":"0.5956293282","4":"-8.5457338","5":"1.299236e-15"},{"1":"stateColorado","2":"-4.4127241692","3":"0.5953924847","4":"-7.4114543","5":"1.945083e-12"},{"1":"stateConnecticut","2":"-6.6325834801","3":"0.5952933996","4":"-11.1417051","5":"1.169797e-23"},{"1":"stateDelaware","2":"-2.4579829953","3":"0.5991822226","4":"-4.1022295","5":"5.546475e-05"},{"1":"stateDistrict of Columbia","2":"-3.5044963616","3":"1.9710939218","4":"-1.7779449","5":"7.663326e-02"},{"1":"stateFlorida","2":"-1.1904908389","3":"0.5959900409","4":"-1.9975012","5":"4.685883e-02"},{"1":"stateGeorgia","2":"-2.4422504400","3":"0.5975174655","4":"-4.0873290","5":"5.890829e-05"},{"1":"stateHawaii","2":"-3.2811475461","3":"0.5978042894","4":"-5.4886651","5":"9.961835e-08"},{"1":"stateIdaho","2":"-1.6145029533","3":"0.6167129515","4":"-2.6179164","5":"9.388795e-03"},{"1":"stateIllinois","2":"-5.2488047162","3":"0.5963135278","4":"-8.8020890","5":"2.304408e-16"},{"1":"stateIndiana","2":"-4.5580058469","3":"0.6088089548","4":"-7.4867589","5":"1.219751e-12"},{"1":"stateIowa","2":"-2.5117857625","3":"0.6116310108","4":"-4.1067011","5":"5.446936e-05"},{"1":"stateKansas","2":"-1.4042963587","3":"0.5953392440","4":"-2.3588170","5":"1.910646e-02"},{"1":"stateKentucky","2":"1.5143772249","3":"0.6006791561","4":"2.5211083","5":"1.232396e-02"},{"1":"stateLouisiana","2":"3.1093174334","3":"0.6148710122","4":"5.0568613","5":"8.270383e-07"},{"1":"stateMaine","2":"-4.0022269640","3":"0.6070911650","4":"-6.5924645","5":"2.566949e-10"},{"1":"stateMaryland","2":"-4.9202430607","3":"0.6090775854","4":"-8.0781877","5":"2.839121e-14"},{"1":"stateMassachusetts","2":"-8.2276855095","3":"0.6009756368","4":"-13.6905475","5":"3.483280e-32"},{"1":"stateMichigan","2":"-5.1840811542","3":"0.5962924572","4":"-8.6938567","5":"4.798059e-16"},{"1":"stateMinnesota","2":"-7.3888657967","3":"0.5962743623","4":"-12.3917214","5":"8.630449e-28"},{"1":"stateMississippi","2":"2.1741873311","3":"0.6065902849","4":"3.5842765","5":"4.066096e-04"},{"1":"stateMissouri","2":"-2.1422872290","3":"0.5958403283","4":"-3.5954049","5":"3.904420e-04"},{"1":"stateMontana","2":"4.6383935108","3":"0.6074334287","4":"7.6360524","5":"4.795866e-13"},{"1":"stateNebraska","2":"-3.9461735450","3":"0.5995547993","4":"-6.5818396","5":"2.728158e-10"},{"1":"stateNevada","2":"-1.9595530016","3":"0.5956187600","4":"-3.2899451","5":"1.146946e-03"},{"1":"stateNew Hampshire","2":"-5.8751508656","3":"0.5971883463","4":"-9.8380200","5":"1.662472e-19"},{"1":"stateNew Jersey","2":"-6.3140121777","3":"0.6063733658","4":"-10.4127466","5":"2.592960e-21"},{"1":"stateNew Mexico","2":"-0.9037640047","3":"0.6151984859","4":"-1.4690608","5":"1.430785e-01"},{"1":"stateNew York","2":"-5.4055532053","3":"0.6080307982","4":"-8.8902622","5":"1.263646e-16"},{"1":"stateNorth Carolina","2":"-1.4618984034","3":"0.5953889564","4":"-2.4553670","5":"1.475848e-02"},{"1":"stateNorth Dakota","2":"0.3585402358","3":"0.5969666397","4":"0.6006035","5":"5.486504e-01"},{"1":"stateOhio","2":"-4.7265870183","3":"0.5953081507","4":"-7.9397317","5":"6.948185e-14"},{"1":"stateOklahoma","2":"0.1990835341","3":"0.5973813359","4":"0.3332604","5":"7.392182e-01"},{"1":"stateOregon","2":"-3.9007020747","3":"0.5994342611","4":"-6.5073059","5":"4.174801e-10"},{"1":"statePennsylvania","2":"-1.7070557163","3":"0.5966638749","4":"-2.8610006","5":"4.581739e-03"},{"1":"stateRhode Island","2":"-6.4092098245","3":"0.5957195832","4":"-10.7587697","5":"2.028760e-22"},{"1":"stateSouth Carolina","2":"3.1378079173","3":"0.6051330489","4":"5.1853190","5":"4.465807e-07"},{"1":"stateSouth Dakota","2":"-0.4374085492","3":"0.6014407918","4":"-0.7272678","5":"4.677451e-01"},{"1":"stateTennessee","2":"0.0748011108","3":"0.6019210702","4":"0.1242706","5":"9.012013e-01"},{"1":"stateTexas","2":"-1.2268812972","3":"0.5952548236","4":"-2.0611027","5":"4.033173e-02"},{"1":"stateUtah","2":"-5.5331388814","3":"0.6174110376","4":"-8.9618399","5":"7.742095e-17"},{"1":"stateVermont","2":"-5.8044649960","3":"0.6422792890","4":"-9.0372912","5":"4.609738e-17"},{"1":"stateVirginia","2":"-4.7176009071","3":"0.5971384048","4":"-7.9003475","5":"8.948304e-14"},{"1":"stateWashington","2":"-6.1580557474","3":"0.5954396533","4":"-10.3420317","5":"4.347999e-21"},{"1":"stateWest Virginia","2":"3.0901095302","3":"0.6240786511","4":"4.9514745","5":"1.359339e-06"},{"1":"stateWisconsin","2":"-4.5709778908","3":"0.6138080620","4":"-7.4469173","5":"1.561890e-12"},{"1":"stateWyoming","2":"0.5124452910","3":"0.5973278354","4":"0.8578962","5":"3.917748e-01"},{"1":"year2008","2":"-1.0106324960","3":"0.2165232747","4":"-4.6675467","5":"4.983806e-06"},{"1":"year2009","2":"-1.6830081686","3":"0.2458855624","4":"-6.8446807","5":"5.933357e-11"},{"1":"year2010","2":"-2.0721270275","3":"0.2751069693","4":"-7.5320776","5":"9.198413e-13"},{"1":"year2011","2":"-2.2176558795","3":"0.3187735015","4":"-6.9568389","5":"3.058267e-11"},{"1":"year2012","2":"-1.8728161563","3":"0.3425094663","4":"-5.4679252","5":"1.105984e-07"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # With plm .quitesmall[ .code60[ ```r fe2_reg_2 <- plm(deaths ~ cell_plans, index = c("state", "year"), model = "within", data = phones) fe2_reg_2 %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"cell_plans","2":"-0.001203742","3":"0.0001013125","4":"-11.88148","5":"3.483442e-26"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] .smallest[ - `plm()` command allows for multiple effects to be fit inside `index=c("group", "time")` ] --- # Adding Covariates .pull-left[ .quitesmall[ - State fixed effect absorbs all unobserved factors that vary by state, but are constant over time - Year fixed effect absorbs all unobserved factors that vary by year, but are constant over States - But there are still other (often unobservable) factors that affect both Phones and Deaths, that *vary* by State *and* change over time! - *Some* States *change* their laws during the time period - State *urbanization* rates *change* over the time period - We will also need to .hi-purple[control for these variables] (*not* picked up by fixed effects!) - Add them to the regression ] ] .pull-right[ 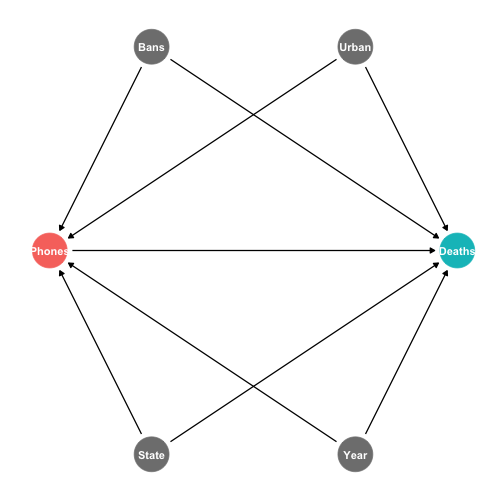<!-- --> ] --- # Adding Covariates I `$$\widehat{\text{Deaths}_{it}}=\beta_1\text{Cell Phones}_{it}+\alpha_i+\theta_t+\text{urban pct}_{it}+\text{cell ban}_{it}+\text{text ban}_{it}$$` - Can still add covariates to remove endogeneity not soaked up by fixed effects - factors that change within groups over time - e.g. some states pass bans over the time period in data (some years before, some years after) --- # Adding Covariates II .quitesmall[ .code60[ ```r fe2_controls_reg <- plm(deaths ~ cell_plans + text_ban + urban_percent + cell_ban, data = phones, index = c("state","year"), model = "within", effect = "twoways") fe2_controls_reg %>% tidy() ``` <div data-pagedtable="false"> <script data-pagedtable-source type="application/json"> {"columns":[{"label":["term"],"name":[1],"type":["chr"],"align":["left"]},{"label":["estimate"],"name":[2],"type":["dbl"],"align":["right"]},{"label":["std.error"],"name":[3],"type":["dbl"],"align":["right"]},{"label":["statistic"],"name":[4],"type":["dbl"],"align":["right"]},{"label":["p.value"],"name":[5],"type":["dbl"],"align":["right"]}],"data":[{"1":"cell_plans","2":"-0.0003403735","3":"0.0001729402","4":"-1.968157","5":"0.05017303"},{"1":"text_ban1","2":"0.2559261569","3":"0.2221923049","4":"1.151823","5":"0.25051208"},{"1":"urban_percent","2":"0.0131347657","3":"0.0111986138","4":"1.172892","5":"0.24197354"},{"1":"cell_ban1","2":"-0.6797956522","3":"0.4029491232","4":"-1.687051","5":"0.09286115"}],"options":{"columns":{"min":{},"max":[10]},"rows":{"min":[10],"max":[10]},"pages":{}}} </script> </div> ] ] --- # Comparing Models .pull-left[ .code50[ ```r library(huxtable) huxreg("Pooled" = pooled, "State Effects" = fe_reg_1, "State & Year Effects" = fe2_reg_1, "With Controls" = fe2_controls_reg, coefs = c("Intercept" = "(Intercept)", "Cell phones" = "cell_plans", "Cell Ban" = "cell_ban1", "Texting Ban" = "text_ban1", "Urbanization Rate" = "urban_percent"), statistics = c("N" = "nobs", "R-Squared" = "r.squared", "SER" = "sigma"), number_format = 4) ``` ] ] .pull-right[ .tiny[ <table class="huxtable" style="border-collapse: collapse; border: 0px; margin-bottom: 2em; margin-top: 2em; ; margin-left: auto; margin-right: auto; " id="tab:unnamed-chunk-38"> <col><col><col><col><col><tr> <th style="vertical-align: top; text-align: center; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><th style="vertical-align: top; text-align: center; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Pooled</th><th style="vertical-align: top; text-align: center; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">State Effects</th><th style="vertical-align: top; text-align: center; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">State & Year Effects</th><th style="vertical-align: top; text-align: center; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">With Controls</th></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Intercept</th><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">17.3371 ***</td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">25.5077 ***</td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">18.9305 ***</td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.9754) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(1.0176) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(1.4511) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Cell phones</th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">-0.0006 ***</td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">-0.0012 ***</td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">-0.0003 </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">-0.0003 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.0001) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.0001) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.0002) </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.0002)</td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Cell Ban</th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">-0.6798 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.4029)</td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Texting Ban</th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.2559 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.2222)</td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">Urbanization Rate</th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.0131 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"></th><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.4pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">(0.0112)</td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">N</th><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">306 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">306 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">306 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0.4pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">306 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">R-Squared</th><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.0845 </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.9055 </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.9259 </td><td style="vertical-align: top; text-align: right; white-space: normal; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">0.0329 </td></tr> <tr> <th style="vertical-align: top; text-align: left; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.8pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">SER</th><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.8pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">3.2791 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.8pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">1.1526 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.8pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;">1.0310 </td><td style="vertical-align: top; text-align: right; white-space: normal; border-style: solid solid solid solid; border-width: 0pt 0pt 0.8pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> </td></tr> <tr> <th colspan="5" style="vertical-align: top; text-align: left; white-space: normal; border-style: solid solid solid solid; border-width: 0.8pt 0pt 0pt 0pt; padding: 6pt 6pt 6pt 6pt; font-weight: normal;"> *** p < 0.001; ** p < 0.01; * p < 0.05.</th></tr> </table> ] ]