Reference
Contents
Look here over the course of the semester for resources, links, and tips on how to succeed in the course, how to write well, and other things of interest related to econometrics, data analysis, managing your worfklow, and using R.
Tips for Success
- Take notes. On paper. Yes. Studies show that using pen and paper trump taking notes on a device. The main reason is because you cannot possibly write down everything I am saying by hand. This forces you to selectively filter my lecture to its most essential and important components – an integral part of the learning and retention process. If you are taking notes on a laptop, you become a court stenographer, thoughtlessly transcribing everything I am saying. At the other extreme, do not assume everything is written in my lecture slides. My lecture slides are visuals and cues to organize the content both for me and for you. I try hard to make sure that I have few words on slides, and even fewer answers to problems.
- My suggestion: print out my lecture slides in advance (or follow along on your device) and take additional notes by hand.
- At least skim all of the readings. I give out readings for a reason, and that reason is not to bore you or waste your time. The truth is, as a beginner, you can’t rely on heuristics or memory to “fill in the blanks.” You need the readings to provide context to what I am saying in class. I cannot help you if you are not going to try. Any professor also will lose patience at short notice when it’s discovered you haven’t done the reading.
- Do the homeworks (if there are any). You might be surprised that I need to say this, but I do. Students that do not do the homeworks do poorly on exams, which often are similar to homework questions. Homeworks are the best practice for exams, they give you a sense of the relevant content areas that might come up, the type and style of questions that I ask, and you often get answer keys to help you “get inside my head” and study from. There is no good reason why you should have a low homework grade.
- Work on assignments together and study together. Recognize that you are not in this alone, and other students are just as anxious or uncertain as you are. More surprisingly, other students probably have some answers you are looking for, and you may have answers for some of their problems! You will learn better when you collaborate with others similar to you. More importantly, you don’t truly understand something unless you can explain it to others.Yes, that means I am doing a ton of learning every time I teach!
As a wise woman once told me “whomever is doing the talking is doing the learning.” - Learn how to learn. The most important skill you learn in college is how to learn. Taking a course on a subject will not make you an expert on that subject. It a) helps you recognize that you do not know everything on that subject, and this prevents you from actively saying stupid things; and b) gives you enough context and skills to figure out how to actually fill those gaps. This is the actual skill that’s relevant in the real world.Yes, Google is your best friend. But you do not yet know how to ask the right questions, or understand what constitutes good answers.
Statistics Resources
A General Symbol Guide
There are a lot of symbols (often greek letters or ligatures on English letters) used in statistics and econometrics. Luckliy, most of them follow some standard patterns, and are consistent across textbooks and research (note there are exceptions!).
| Style | Examples | Meaning |
|---|---|---|
| Greek letters | β0,β1,σ,u | True parameters of population |
| Hats | ^β0,^β1,ˆσ,ˆu | Our statistical estimates of population parameters, from sample data |
| English capital letters | X1,X2,Y | (Random) variables in our sample data |
| English lowercase letters | x1i,x2i,yi | Individual observations of variables in our sample data |
| Modified capital letters | ˉX,ˉY | Statistics calculated from our sample data (e.g. sample mean) |
| Bold capital letters | X=[x1,x2,⋯,xn] β=[β1,β2,⋯,βk] | Vector or matrix |
Sample Statistics vs Population Parameters Formulae
| Sample | Population | |
|---|---|---|
| Population | n | N |
| Mean | ˉx=1nn∑i=1xi | μ=1NN∑i=1xi |
| Variance | s2=1n−1n∑i=1(xi−ˉx)2 | σ2=1NN∑i=1(xi−μ)2 |
| Standard Deviation | s=√s2 | σ=√σ2 |
R Resources
Installing R and R Studio
As of June 22, 2020, the latest release of R is R version 4.0.2 (2020-06-22) -- "Taking Off Again". Make sure you have at least R version 4.0.0 (2020-04-24) -- "Arbor Day".
- Install R from CRANThe Comprehensive R Archive Network
by clicking “Download R” (or the CRAN link under Downloads on the left menu). This will take you to a mirrors page, where you can select a location in the U.S. and download a copy of R - Install R Studio (Desktop Version), choose the “Free” option
R Packages
Packages come from multiple sources.
The polished, publicly released versions are found on CRAN. When installing a package available on CRAN, it is sufficient simply to tell R the following:Note the plural s on packages, and the quotes around the “package name”
install.packages("packagename") Other packages, which may be in various developmental states (including perfectly functional!) are often hosted on GitHub before they make their way onto CRAN. Simply telling R install.packages("packagename") will fail to find it (as R only looks in CRAN for packages), so you must use another package called devtoolsWhich you will need to install first if you (probably) don’t already have it!
to install packages directly from Github:Note the :: allows you to use the function install_github() from the devtools package without having to first load the devtools package with library(devtools).
devtools::install_github("username/packagename") For example, to install Hadley Wickham’s package r4ds from its Github page https://github.com/hadley/r4ds, we would type:
devtools::install_github("hadley/r4ds")Getting Help for R
For specific functions or commands, you can simply type:
?functionname()
# example
?mean()This will display a help page specific to that function in the Viewer pane. R functions and packages are extremely well-documented; help pages normally include a short description of the function, arguments and options (as well as their default values), and several examples or vignettes to demonstrate usage of the function.
Additionally, you can turn to the community.
Cheat Sheets
R Packages
The following is a compendium of all R packages used in this course, their main uses, and when we use them
Note: ggplot2, tibble, magrittr, dplyr, readr are all part of the tidyverse.
| Name | Type | Description/Reason(s) for Use | Classes Used |
|---|---|---|---|
ggplot2 |
Plotting | For nice plots | [1.3] |
haven |
Data Wrangling | For importing nonstandard data files | [1.4] |
dplyr |
Data Wrangling | For manipulating data (part of tidyverse) | [1.4] |
readr |
Data Wrangling | For importing most data files | [1.4] |
tidyr |
Data Wrangling | For reshaping data (wide and long) | [1.4] |
magrittr |
Data Wrangling | For the pipe | [1.4] |
tibble |
Data Wrangling | For a friendlier data.frame | [1.4] |
car |
Models | For testing for outliers | |
estimatr |
Models | For calculating robust standard errors | |
lmtest |
Models | For testing for heteroskedasticity | |
broom |
Models | For tidying regression output | |
gganimate |
Plotting | For animating plots | |
huxtable |
Models | For making nice regression tables | |
ggtext |
Plotting | For using markdown in text (labels, axes) | |
ggrepel |
Plotting | For annotating text that doesn’t cover observations | |
patchwork |
Plotting | For aligning multiple plots into a single figure | |
infer |
Models | For simulation and statistical inference | |
kable |
Output | For outputting nicer tables | |
ggdag |
Plotting | For plotting DAGs in ggplot | |
plm |
Models | For working with panel data |
R Markdown Resources
Math and LATEX
Math in R Markdown uses the LATEX language to typeset beautiful formulas and equations. To include mathematical symbols or expressions inlineThat means, within the text, and not in a separate line, location, or environment within the document.
, insert it $between two dollar signs$. Within a sentence, $2^2+\frac{\pi}{\pi}=5$ becomes 22+ππ=5.
If you prefer it to be centered in its own line, put it on its own line, $$between two dollar signs$$.
`‘‘2^2+\frac{\pi}{\pi}=5‘‘ becomes:
22+ππ=5
Most common math symbols
| Use | Code |
|---|---|
| Exponent (superscript) | x^2 |
| Subscript | x_i |
| Modifications (hats, bars) | \hat{x}, \bar{x} |
| Fractions | \frac{numerator}{denominator} |
| Arrows | \leftarrow, \rightarrow |
| Implications | A \implies B, A \iff B |
| Text inside equations | \text{Write text here} |
| Greek letters (lowercase) | \alpha, \beta , etc. |
| Greek letters (uppercase) | \Alpha, \Beta , etc. |
| Summation operator | \sum^{n}_{i=1} |
This will get you 95% of the way, but there are some times when you need to know a few advanced tricks. Here are a few of those times:
- Overhead modifications on long terms look bad, here are some fixes:
| Instead | of | Try | Instead |
|---|---|---|---|
\hat{\text{A very long term}} |
^A very long term | \widehat{\text{A very long term}} |
^A very long term |
\bar{\text{A very long term}} |
¯A very long term | \overline{A very long term} |
¯A very long term |
- Very large symbols, such as the summation operator, may be squished if used inline (one
$) (as opposed to a centered equation, two$$s). To prevent this when in-line, insert\displaystylein front of it. That’s the difference betweeen\sum^{n}_{i=1}: ∑ni=1 and n∑i=1.
Producing documents
Producing a PDF Output
PDFs are archaic document formats with many flaws, yet the format remains the industry standard in most cases. PDFs are made with LATEX, a typography language dating to the 1980s. LATEX has its own problems
One alternative is tinytex
install.packages("tinytex")
tinytex::install_tinytex() # install TinyTeXData Resources
List of Public Datasets, Data Sources, and R APIs
Build-in Datasets
- A near-comprehensive list of all existing data sets built-in to R or R packagesNote: You should use these more for playing around with in R to boost your data wrangling skills. These should not be used for your projects in most circumstances.
General Databases of Datasets
Good R Packages for Getting Data in R FormatSome of these come from Nick Huntington-Klein’s excellent list.
Below are packages written by and for R users that link up with the API of key data sets for easy use in R. Each link goes to the documentation and description of each package.
Don’t forget to installinstall.packages("name_of_package")
first and then load it with library().
wbstatsprovides access to all the data available on the World Bank API, which is basically everything on their website. The World Bank keeps track of many country-level indicators over time.tidycensusgives you access to data from the US Census and the American Community Survey. These are the largest high-quality data sets you’ll find of cross-sectional data on individual people in the US. You’ll need to get a (free) API key from the website (or ask me for mine).fredrgets data from the Federal Reserve’s Economic Database (FRED). You’ll need to get a (free) API key from the website (or ask me for mine).tidyquantgets data from a number of financial sources (includingfredr).icpsrdatadownloads data from the Inter-university Consortium for Political and Social Research (you’ll need an account and a keycode). ICPSR is a database of datasets from published social science papers for the purposes of reproducibility.NHANESuses data from the US National Health and Nutrition Examination Survey.ipumsrhas census data from all around the world, in addition to the US census, American Community Survey, and Current Population Survey. If you’re doing international micro work, look at IPUMS. It’s also the easiest way to get the Current Population Survey (CPS), which is very popular for labor economics. Unfortunately ipumsr won’t get the data from within R; you’ll have to make your own data extract on the IPUMS website and download it. But ipumsr will read that file into R and preserve things like names and labels.education-data-package-rNote you will need to installdevtoolspackage first, and then install the package directly from Github with the commanddevtools::install_github('UrbanInstitute/education-data-package-r')
is the Urban Institute’s data data on educational institutions in the US, including colleges (in IPEDS) and K-12 schools (in CCD). This package also has data on county-level poverty rates from SAIPE.psidRis the Panel Study of Income Dynamics. This study doesn’t just follow people over their lifetimes, it follows their children too, generationally! A great source for studying how things follow families through generations.atusis th e American Time Use Survey, which is a large cross-sectional data set with information on how people spend their time.Rilostatuses data from the International Labor Organization. This contains lots of different statistics on labor, like employment, wage gaps, etc., generally aggregated to the national level and changing over time.democracyDataNote you will need to installdevtoolspackage first, and then install the package directly from Github with the commanddevtools::install_github('xmarquez/democracyData')
is a great “package for accessing and manipulating existing measures of democracy.”politicaldataprovides useful functions for obtaining commonly-used data in political analysis and political science, including from sources such as the Comparative Agendas Project (which provides data on politics and policy from 20+ countries), the MIT Election and Data Science Lab, and FiveThirtyEight.
Below is a list of good data sources depending on the types of topics you might be interested in writing on:Some of these come from various sources, including https://github.com/awesomedata/awesome-public-datasets#economics
Key Data Sources
Coronavirus Data: John Hopkins CSSE Covid-19 data (definitive), Our World in Data, New York Times Covid data,
covdatar package, Tidy Covid data
By Topic
- Quality of Government Data has an extremely wide range of data sources pertaining to measures of institutions. The data itself can be found here.
- National and State Accounts Data: Bureau of Economic Analysis
- Labor Market and Price Data: Bureau of Labor Statistics
- Macroeconomic Data: Federal Reserve Economic Data (FRED), World Development Indicators (World Bank), Penn World Table
- International Data: NationMaster.com, Doing Business, CIESIN
- Census Data: U.S. Census Bureau
- Sports Data: Spotrac, Rodney Fort’s Sports Data
- Data Clearing House: Stat USA, Fedstats, Statistical Abstract of the United States, Resources for Economists
- Political and Social Data: ICPSR, Federal Election Commission, Poole and Rosenthal Roll Call Data (Voting ideology), Archigos Data on Political Leaders, Library of Congress: Thomas (Legislation), Iowa Electronic Markets (Prediction Markets)
- War and Violence Data: Correlates of War
- State Level Data: Correlates of State Policy
- Health Data: Centers for Disease Control, CDC Wonder System
- Crime Data: Bureau of Justice Statistics
- Education Data: National Center for Education Statistics
- Environmental Data: EPA
- Religion Data: American Religion Data Archiva (ARDA)
- Financial Data: Financial Data Finder{Financial Data Finder}
- Philanthropy Data: The Urban Institute
How to Make a PDF (For Submitting Assignments)
Using an App on Your Phone
There are many good apps out there that will allow you to take photos and convert them to PDFs. This is actually a better method than using your computer (described below), since theses apps optimize your photos for PDFs (using your computer to convert will often result in very large PDF file sizes!). Here are a few apps you can use:
- Scannable If you use Evernote for notes (I do, it’s amazing), this can sync up and store your PDFs in Evernote
- Turboscan
- Image to PDF Converter Free
- PDF Converter Pro
- Simple Scan
Personally, I use Scannable — primarily because of its association with Evernote, if you wanted a recommendation. But note it does not exist on Android. I also have successfully used Turboscan in the past.
Additionally, as Hood students, you all have Onedrive, you can use the app on your phone to scan documents with photos and convert them to PDFs.
Using Images Sent to Your Computer
Most modern versions of operating system have a built-in tool in the File Viewer (or Finder) menus, after clicking on one or multiple files, to create a PDF from the files.
So first take photos on your smartphone of your written work (one photo per page). Please try to frame your photos properly! Put your paper flat on a solid surface (table, desk, the floor, etc). Get the whole page within the borders of the photo, and not too much background. I don’t need to see half of your desk or bed as you are taking the photo! Take a look at it and make sure it is legible.
Next, get the photos onto your computer (whether by Airdrop, email to yourself, Dropbox, etc.). Finally, depending on your OS, convert the files to a PDF:
1. On a Windows PC
Open the folder where your photos are currently, in the File Explorer. Select all of the photos, and right click, and select Print. In the dialog box that pops up, select Microsoft Print to PDF in the Printer box, and then click Print. This will save it as a .pdf file in that folder. See more information.
2. On a Mac
As I use a Mac, I will show you how Mac OS has a neat feature built into Finder, which allows converting multiple files into a single PDF file as a Quick Action. I have written two pages in a notebook and taken two separate pictures of them, and airdropped them onto my computer.
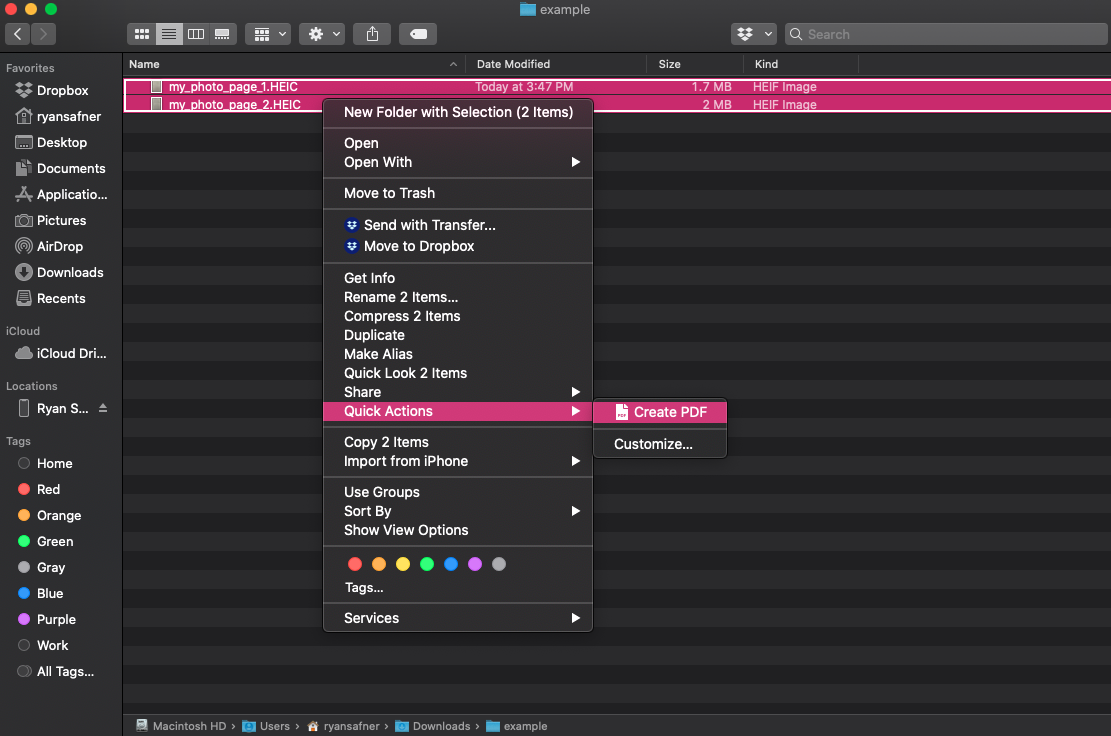
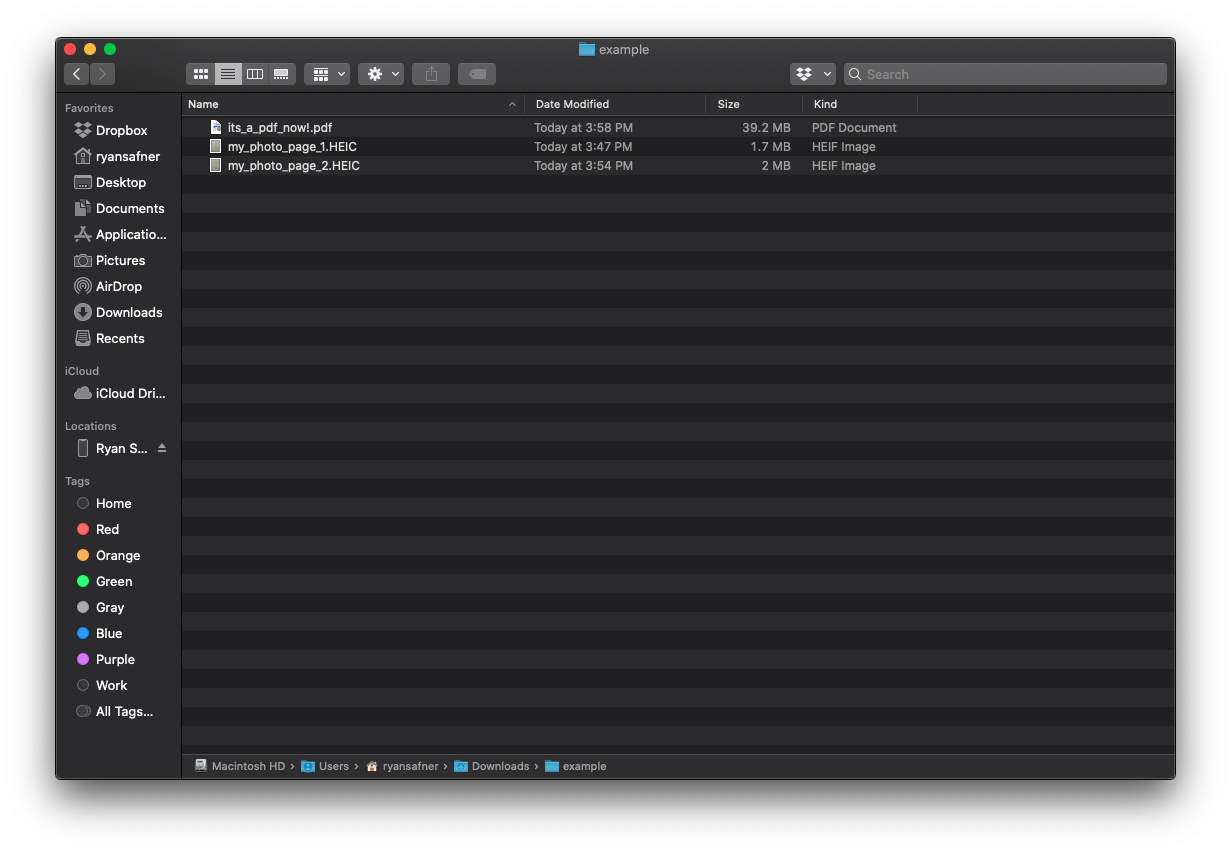
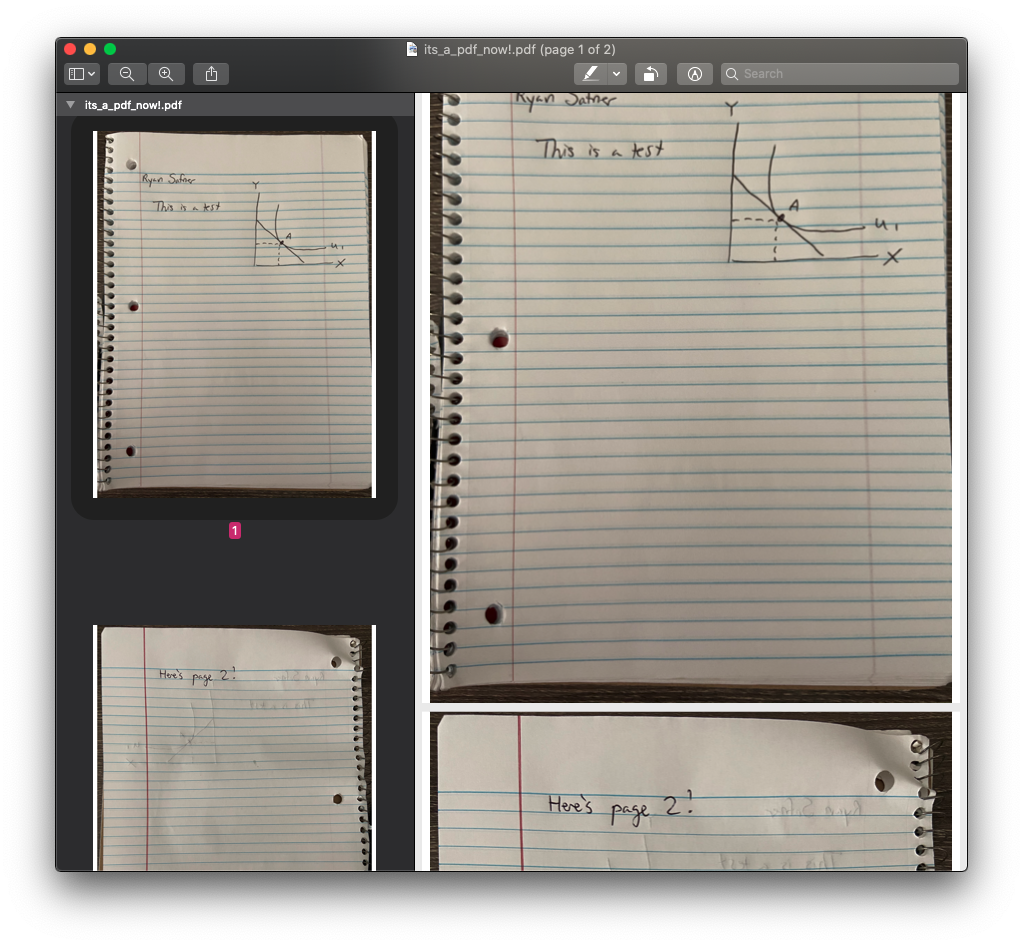
Here is the example PDF.